
计算机组成原理
计算机的基本结构
计算机的类型
嵌入式计算机(embedded computer):专门为单个功能设计的计算机,集成于各种家电,交通工具等,集成(integrated)
个人计算机(Pc):以个人为单位的计算机,支持使用各种软件,主要用于个人用途。在此之下还有台式计算机(desktop computer)和工作站计算机(workstation computer),后者专为工程而生,具有强大的计算和图像显示能力。
服务器(server)和企业系统(enterprise system)由许多用户共用的计算机,通过网络连接
超级计算机(super computer)和网格计算机(grid computer):后者是组合了PC和工作站计算机的网格式计算机
云电脑(cloud ocmputer)
功能部件(注-填空)

五大元件:输入设备,输出设备,存储器,ALU,控制器(合成处理器)
存储器(memory):
分为主存(main memory)和辅助存储器(secondary storage)。
主存
主存为RAM,更快的RAM被称为高速缓存,与处理器紧密联系,用于存储指令以及提高指令运行速度。
主存由大量半导体存储单元组成
辅助存储器(secondary storage)
包括磁盘,光盘和闪存设施,
运算器
包含ALU和寄存器
寄存器的速度大于高速缓存
基本操作

主存一般存储程序,当需要执行程序时,程序计数器(PC) 指向下一个执行的程序的地址,并将此程序发向存储器,以读信号读出寻找的程序,读出后装入寄存器 指令寄存器(IR), 以便直接解释以及执行。
pc指向下一个指令->读取存储器中的指令->存储到IR->加载到ALU计算->运算结果存取在寄存器中->写入存储器。
补充:处理器中存在MDR与MAR,分别起传递数据(data)和地址的作用。故又有流程:pc指向下一个程序—-将此指令发送至MAR(pc指向的指令地址)———MAR将指令发送到主存——-主存按指令提取到pc指向的指令——传送到MDR(将指令转化为二进制数据)——-数据传递到IR——-IR转化为可执行的指令(以load为例,即加载数据到指定位置)———指令传递到MAR———-到主存拿到数据———-传递到MDR———传递到处理器寄存器中。
中断
用于暂停程序的运行,处理器执行中断服务程序(interrupt-servicr routine)并将处理器的状态信息存储到存储器,恢复时载入。中断只能在IR当前执行的指令完成后进行。
浮点数:小数点的位置会根据数值而变化
电气电子工程师学会IEEE
并行
指令级并行:在执行指令的同时加载指令
多核(core)处理器:在一个芯片上放置多个处理单元
多处理器:存在多个处理器,每个处理器又包含多个核。
历史(注-选择)
第一代
1945-1955
真空管(Vacuum tubes),磁芯存储器(magnetic core),磁鼓存储器(magnetic drum),汇编语言
第二代
晶体管(transistors),磁盘(magnetic disk),高级语言
第三代
集成电路(integrated circuits),
第四代
VISL,LSI等超大规模集成电路
习题
1 . Which of the following is an example of bothinput and output device?
A. Touchpad B. Display C. Printer D. Keyboard
A
2 . List the names of five functional units of a computer.
运算器,控制器,输入,输出,存储器
3 . Which technology marked the start of the first/second/third generation of electronic digital computers?
A. integrated-circuit
B. VLSI
C. transistor
D. vacuum tube
总结
本节主要考点:计算机的五大功能部件,计算机的发展史
算数运算(Arithmetic)
三种大题三选一
数的表示及算数运算
原码:数的绝对值表示
带符号原码(signed-Magnitude representation):仅拓展了符号位
反码(one’s complement):原码所有位取反得到
补码(two’s complement):反码末位加1得到
正数在加法运算中不需要改为补码,在减法运算中作为减数需要变为补码。负数在减法运算中作为被减数需要变为1次补码,减数则需要两次,即变为对应的正数。
溢出
同号补码相加符号相反表示结果溢出,单纯的符号位进位不一定是溢出
最高位(MSB)
当计算结果出现颠倒,例如-6-7得到正数,此时我们称为溢出;若符号位1+1进位,但结果与预期一致,则不是溢出
实际
假若x-y中y=7,那么-y的补码表示为:y的无符号原码取反加1;
若x-y中y=-7,那么-y的补码表示为:y的原补码表示取反加1;
习题
(数的表示部分)
- Question 1: Which representation is the most efficient method for performing addition and subtraction operations?
- Options:
- A. Signed-Magnitude Representation;
- B. Signed 1’s Complement Representation;
- C. Signed 2’s Complement Representation;
- D. None of the above.
- Answer: C.
- Question 2: What is the range of an 8 -bit signed 2’s complement integer?
- Options: A. [-256, +256]; B. [-256, +255]; C. [-128, +128]; D. [-128, +127].
- Answer: D. According to the range of n -bit Two’s-complement integer mentioned in the document, which is $-2^{n - 1}$ to $2^{n - 1}-1$. For 8 bits, it is $-2^7$ to $2^7 - 1$, that is [-128, +127].
- Question 3: Given the 8 -bit binary number 10011101, what decimal number does this represent if the computer uses signed-magnitude representation?
- Options: A. +29; B. -29; C. +99; D. -99.
- Answer: D. 原码表示,直接取绝对值
- Question 4: Given the 8 -bit binary number 10011101, what decimal number does this represent if the computer uses signed two’s complement representation?
- Options: A. +29; B. -29; C. +99; D. -99.
- Answer: D. 补码表示,取反加1,再看原符号位
(计算部分)
1 . Assume that X and Y are two 8-bit signed two’s complement numbers 01011110 and 11001010. What is the result of X+Y?
A. 00101000
B. 10010100
C. 01000100
D. 00011100
A,直接计算即可
2 . Assume that X and Y are two 8-bit signed two’s complement numbers 01011110 and 11001010. What is the result of X-Y?
A. 00101000
B. 10010100
C. 01000100
D. overflow
D,Y取反加1后计算,发现两个符号位为0的数得到符号位为1的结果,溢出
3 . True or False? Subtracting a negative integer from another negative integer in 2’s-complement binary arithmetic can cause an overflow.
错,符号位都不相同,不满足溢出的前提条件
有符号数加减法
全加器(full adder FA)
行波进位加法器(ripple-carry adder)
最低有效位(LSB)
用于反码加1得到补码
单位

全加器如图,有进位输入及进位输出,输入两位以得到加法结果。
求和结果为三值的异或,进位输出的结果为$c_{i+1}=yc_i+xc_i+xy$
级联

由此得到了k个n为加法器的级联,即行波进位加法器。

其中,每个全加器都可控制加法与剑法输入。
溢出检测
对有n位的两个数,$overflow=c_n\oplus c_{n-1}$
若为1,则两个数的求和溢出
$Overflow =x_{n-1} y_{n-1} \overline{S}_{n-1}+\overline{x}_{n-1} \overline{y}_{n-1} s_{n-1}$此公式也可以判断(由最小项结合真值表推出)
延迟分析
求和结果比进位结果提前一个周期得到
由此得到,对n位的数据求和,和结果在2n-1时出现,进位结果在2n时出现
习题
1 . In a 1-bit full adder, which expression is $s_{i} ?$
$A. x_{i}+y_{i}$
$B. x_{i} \oplus y_{i}$
$C. x_{i} y_{i}$
$D. x_{i} \oplus y_{i} \oplus c_{i}$
D
2 . In a 1-bit full adder, which expression is c $C_{i+1} ?$
$A. x_{i}+y_{i}+c_{i}$
$B. x_{i} y_{i} c_{i}$
$C. x_{i} y_{i}+x_{i} c_{i}+y_{i} c_{i}$
$D. x_{i} \oplus y_{i} \oplus c_{i}$
c
3 . If we want to construct a 64-bit adder, how many adders do we need if we have some 4 -bit ripple carry adders?
A. 32 B. 16 C. 8 D. 4
B
快速加法器设计
超前进位加法(Carry-Lookahead addition)

此公式推出得到进位的公式,可由前一个进位和G_i和P_i得到,两者分别称为生成函数和传播函数。依次带入C_i,可得到

于是,每一位的进位输出和输入都能够快速完成了
单位

其基本单位如上:
每个单位的G与P都可同步算出,记为一次门延迟;带入计算进位输出的式子,可得所有进位在三个门延迟内完成;结果需要进位信息,因此需要4个门延迟后得到;
整体

如上图,扩展得到4位超前进位加法器
扇入限制(Fan-In)

8个4位超前进位加法器级联得到32位超前进位加法器。该加法器的G与P也是同步计算的,故得到所有的进位信息需要3+(8-1)*2=17个门延迟,而和需要17+1=18个门延迟。
改进

以相同的方式组装得到16位超前进位加法器

由此公式得到,生成$P^,G^$需要两个和三个门延迟,子元件的$P^,G^$构成了大元件的P,G,故得到所有的进位需要5个门延迟。在第5个周期时,所有的块得到进位输入以及输出;在第七个周期时,所有的块内部的单元得到进位输入以及输出;在第八个周期时所有的单元得到和
故需要5个门延迟得到进位和8个门延迟得到和
行波进位加法器与超前进位的比较
行波进位加法器需要的空间少,电路不复杂,成本低,但速度慢
超前进位需要的空间大,电路复杂,对元器件的要求高,成本高,速度快
习题
1 . A 16-bit ripple-carry adder is used to add two numbers X(x15x14…x1x0) and Y(y15y14…y1y0) to generate a 16-bit sum S(s15s14…s1s0). How many gate delays are required to compute s13 after all the inputs have been applied?
A. 8 B. 25 C. 27 D. 31
B,计算第13位,带入公式,求和需要25个周期,进位需要26个周期
2 . The advantage of carry-lookahead adder is__.
A. Optimize the structure of the adder
B. Save hardware parts
C. Augment the structure of the adder
D. Accelerate the generation of the carries
B
3 . In carry-lookahead adder, which expression is called the propagate function Pi for stage i?
A. $xi+yi$
B. $xi⊕yi$
C. $xiyi$
$D. x_{i} \oplus y_{i} \oplus c_{i}$
C
4 . In carry-lookahead adder, which expression is called the generate function Gi for stage i?
A. xi+yi B. xi⊕yi C. xiyi D. xi⊕yi⊕ci
A
5 . Ture or False?
In a 4-bit carry-lookahead adder, all carries can be obtained 3 gate delays after the input signal X, Y and c0 are applied.
True
无符号数乘法(multipication of unsigned numbers)
陈列
阵列乘法器(了解即可)

乘法原理:根据1/0得到加数,再进位进行加法。
单位

使用全加器(FA),q_i为乘数,m_j为被乘数,二者不变而在阵列中传递。进位输入输出是ldx了,向下传递最高位的进位输出
整体

斜向传递的是被乘数,横向贯穿的是乘数。
从横向上:每个单元交流进位;
纵向上:每个单位将最高有效位的进位传递到下一组加法,将每次进位产生的单独一位传下
顺序电路乘法器(sequence Multiplication)(注-大题)
整体

C储存最高有效位的进位,寄存器A记载每次加法的和,乘数Q记载乘数(Multoplier),M记载被乘数(Multiplicand)。这三个元件一体,每次向右移位。控制序列发生器检测Q中的第一个元素,为一则进行加法,得到各个数据然后移位;为0则不进行加法,但是仍要移位。进行n次后就得到了乘法结果。
记住公式$M*Q=A+c$

由上图可知:
检测为1,加法启动,然后移位,最高有效位未产生进位,c为0;
检测为1,加法启动,c进为1,然后移位;
检测为0,不加,移位;
检测为1,加法启动,移位。
完成;
习题
Multiply A and B (unsigned numbers) using sequential multiplication. Assume that A is the multiplicand and B is the multiplier.
A= 00101 and B=10101
注意:
- 取和是将A和M的内容相加
- 不需要补充位数
有符号数乘法(Multiplication of signed Numbers)(注-)
Booth算法

此图简单的理解方式是从右向左扫描,遇到1就记为-1,若左侧是0,则把0记为+1,反之记为0;
将乘数转化为booth格式,遇到-1即将被乘数转化为补码,遇到+1则保持不变。乘数右侧补零,中间值按符号扩位
| 0 | 1 | 1 | 0 | 1 | 1 | 1 | _0_ |
|---|---|---|---|---|---|---|---|
| +1 | 0 | -1 | +1 | 0 | 0 | -1 |
流程表示
当$Q_1$和$Q_{-1}$为上述的组合时,执行对应的操作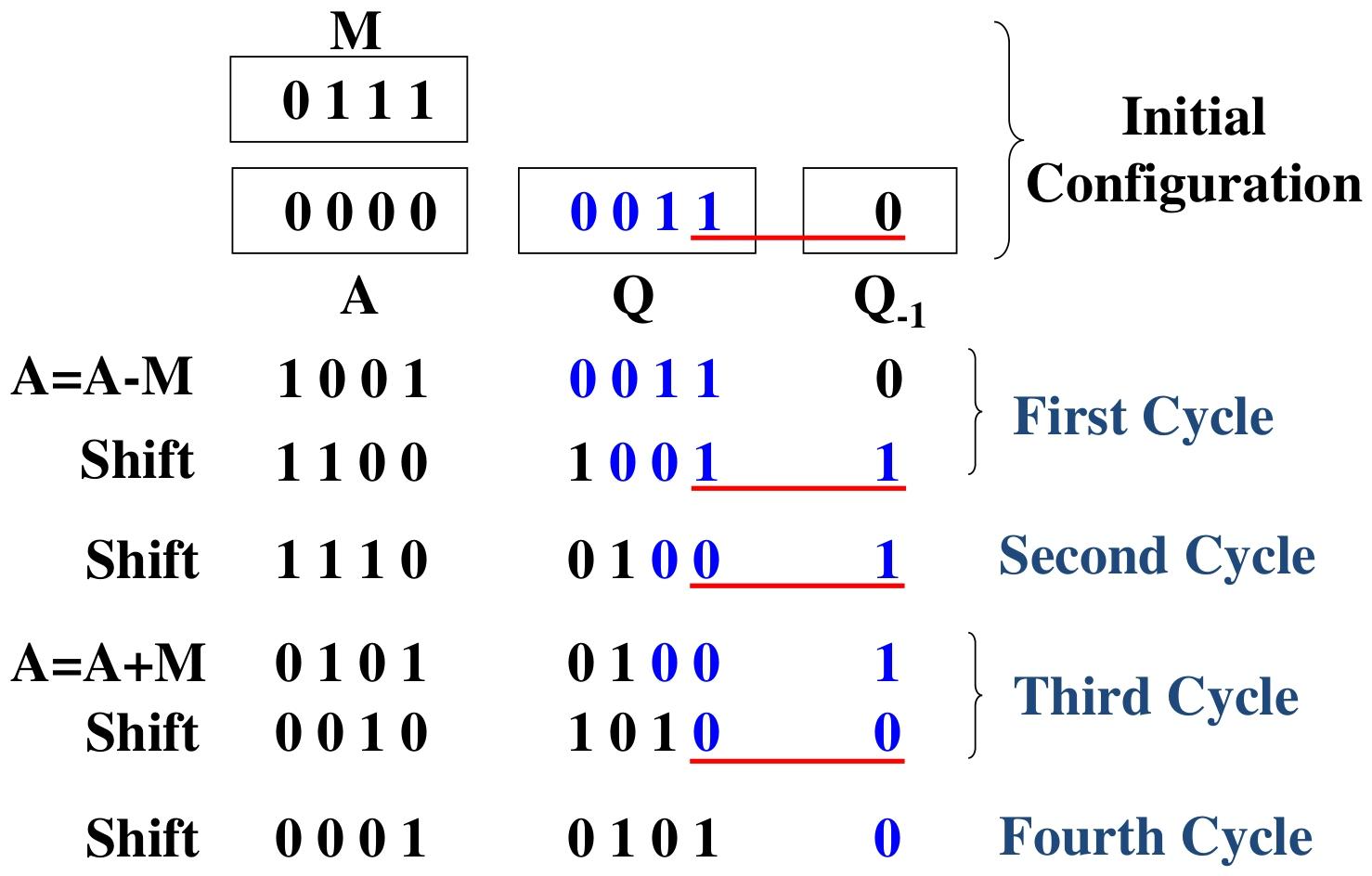
结果为AQ
手算表示
设被乘数为0110011,则
| 0 | 1 | 1 | 0 | 0 | 1 | 1 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| X | +1 | 0 | -1 | +1 | 0 | 0 | -1 | ||||||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||
| 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | |||
| 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | ||||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||||
| 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | ||||||
| 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 |
| 符号位 |
忽略最高有效位的进位。
得到的符号位是0,故不需要求补,反之需要求补码
算术右移,保留符号位(?)
习题
1 . In the hardware circuit of implementing Booth algorithm, the multiplier is placed in the Q register. And a 1-bit register $Q_{-1}$ is placed logically to the right of the least significant bit $(Q_{0})$ of the Q register. The results of the multiplication will appear in the A and Q registers. At the end of each cycle of computing the product, A, Q, $Q_{-1}$ are __ one bit position.
A. shifted left B. shifted right
C. arithmetically shifted left D. arithmetically shifted right
D,算术右移,保持符号不变
2 . About Booth algorithm, which of the following is not true?
A. It can handle both positive and negative multipliers uniformly
B. It achieves some efficiency in the number of additions required when the multiplier has a few large blocks of 1s
C. Its speed of doing multiplication is always faster than the normal algorithm D. The multiplier 111100110 will generate three partial products
C,Booth只能化简大块聚集的1,01010101的效率可能更差
3 . What are the main advantages of the Booth algorithm?
– Directly handle the multiplication with the signed numbers
– Fewer partial products generated for groups of consecutive 0’s and 1’s
4 . Multiply A and B (2’s-complement numbers) using the Booth algorithm. Assume that A is the multiplicand and B is the multiplier.
$A=110011 and B=101100$
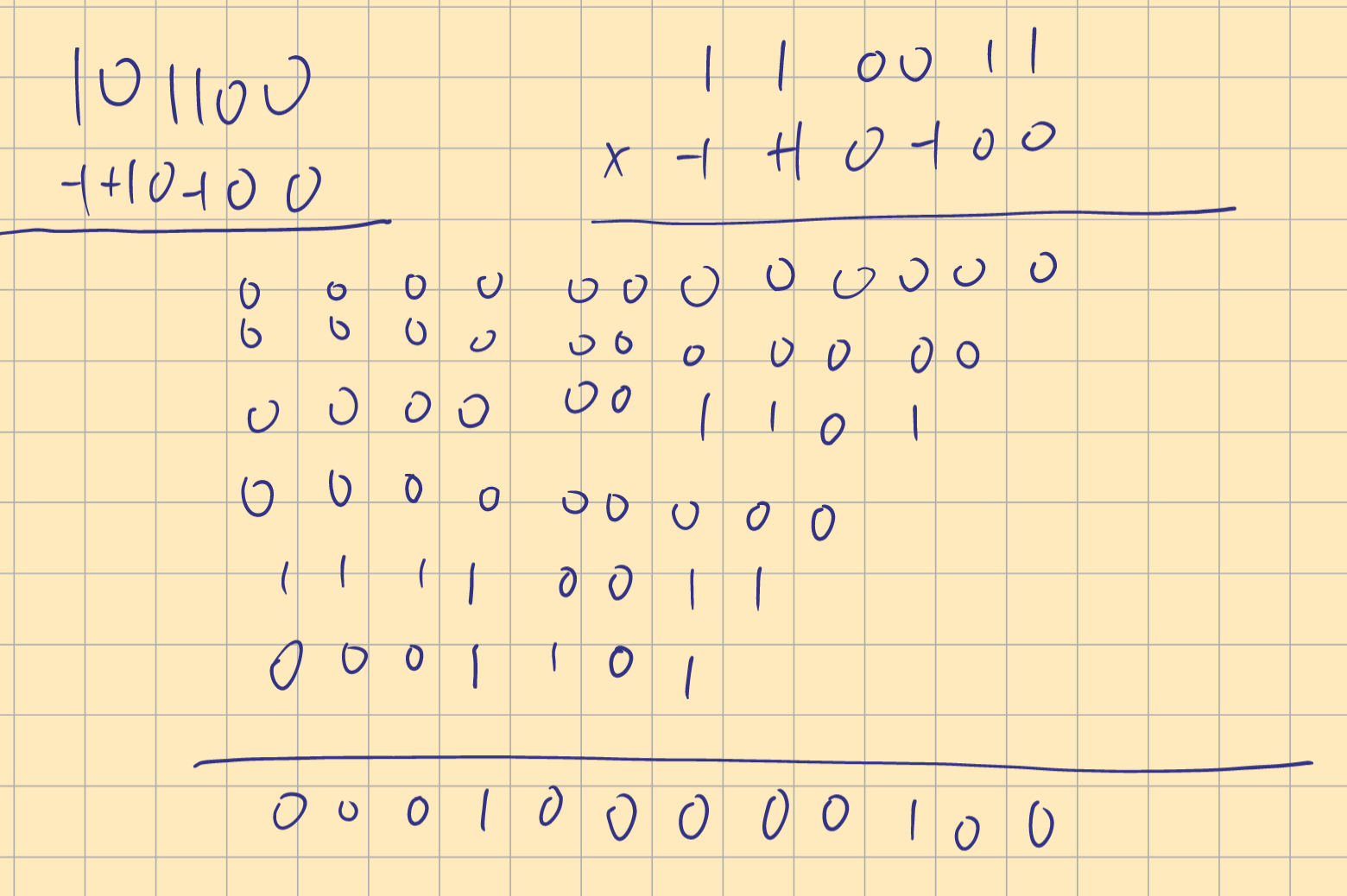
注意:乘数中的-1表示对被乘数取反加1(一般会使符号相反),符号以取反加1的结果为主

注意:结果为A和Q中的内容,减法为A-M而不是M-A
快速乘法
乘数位偶重编码(Multiplier Digit Even-Weighted Encoding)(注-)
对booth格式的乘数进行重编码
要求乘数是4的倍数,转换规则如下
先转换为booth
再使用下表再次进行缩少一半的转换
| booth(i+1) | booth(i) | 乘数位偶重编码 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | -1 | -1 |
| 0 | +1 | +1 |
| -1 | 0 | -2 |
| +1 | 0 | +2 |
| -1 | +1 | -1 |
| +1 | -1 | +1 |
给出例子,每次乘法向前进两位
| 0 | 1 | 1 | 0 | 1 | |||||
|---|---|---|---|---|---|---|---|---|---|
| X | 0 | -1 | -2 | ||||||
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 |
| 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | ||||
| 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 |
求和项的进位保留加法


可通过模拟手动求和来推断行波进位阵列

将同时求和位数加到了3而已
使用3-2简化器的求和项加法树

即将$6*6$位的乘法每项求和,简化为对每三项求和(直接相加,不再计算)与进位,再组合得到答案。大部分步骤可以同时进行

使用4-2简化器的求和项加法树
整数除法
整体上使用逻辑左移的思想
恢复除法(restoring division)(注-)

恢复除法的核心思想是若进行计算,则再进行一次运算以得到原数。
增加一位表示符号
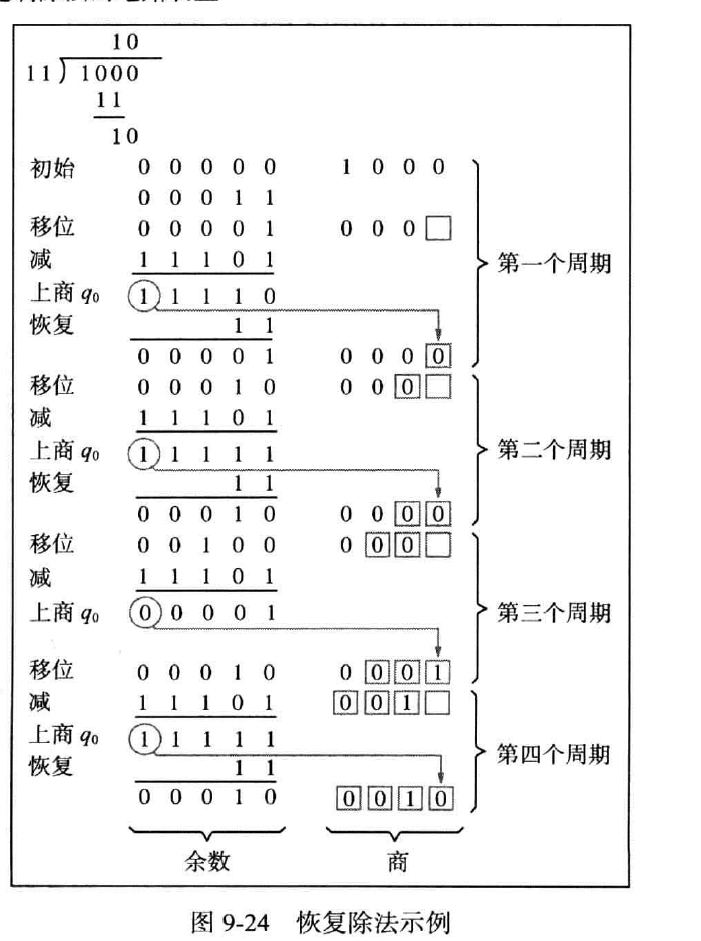
把除法试想为减法,若被减数大于减数,则取一进行减法,反之得到原数之后取零。
步骤
A,Q左移一位
A减去M,结果放回A
若A的符号为1(A<M),上商取0,将M加回到A以得到A;否则商取为1,不再恢复。
不恢复除法(Non-Restoring)(注-大题)
M,A增加一位表示符号

步骤
若A的符号为0,则左移后A-M;反之左移后A+M
得到新的A的值后,若A的符号为0,商取为1;反之为0
习题
• Using non-restoring division algorithm, perform the operation A÷B on the 4-bit unsigned numbers A= 0111 and B= 0011.
值得注意的是:
- 恢复除法中商和余数已经自动算出
- 不恢复除法中,余数需要判断:
- 若结果中A的符号位是0,则就是余数
- 否则,加上除数来恢复到余数
浮点数(FP)及其运算(注-大题,填空)
定点数(Fixed-point)
根据小数点位置,有不同的表示范围,例如纯小数(pure-fraction)的范围为:$-1到1-2^{-n}$
浮点数
主要考察表示(包括正规IEEE规定和题目规定),少部分考察计算(加减)
分为单精度和双精度

一个计算机必须至少提供单精度的数值表示
均有三部分:
符号位S
为1时表示正值,反之为负值
余数E‘(exponent)
$E^=E+(2^{n-1}-1),E^$为无符号数,+127是为了方便区分正负数的大小,注:对n位的余数部分,+的值为$2^{n-1}-1$。
$E^`$的范围是$0到2^n-1$,两个端点值是特殊值,E的范围是$-2^{n-1}+1到2^{n-1}$,两个端点值同样是特殊值,一般不会取该值
尾数M(mantissa)
一般情况下值为1.M
表示范围是$1.0000…到2-2^{-23}$
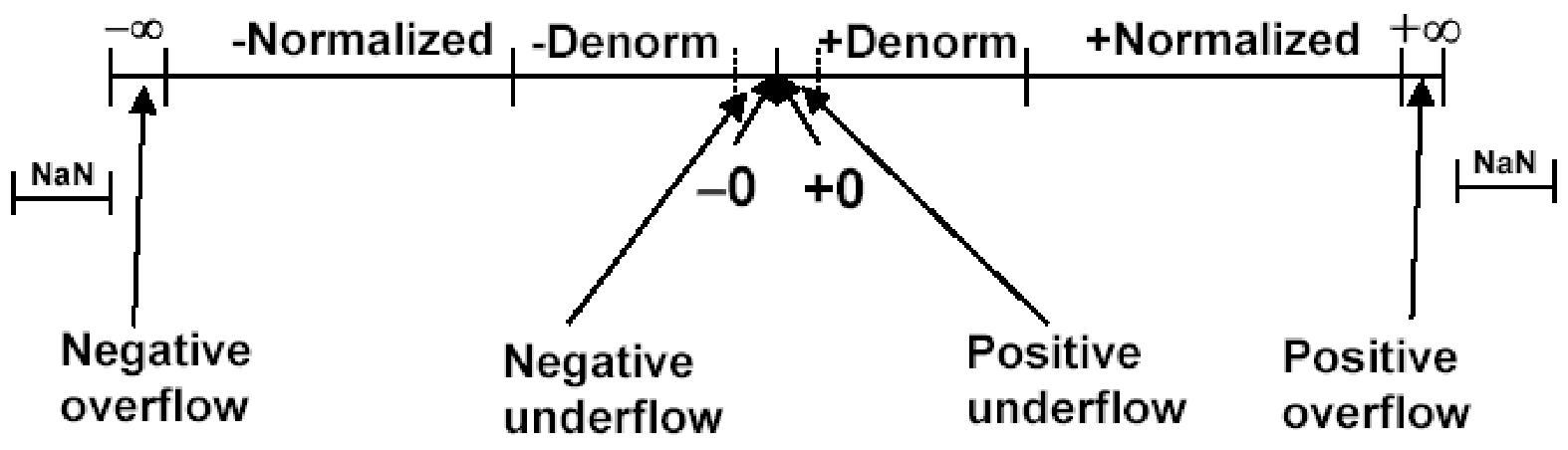
特殊值
$E^=0$表示尾数上没有隐含的1,即**非规格数(Denormal number)**;相反为**规格数(normal)**
当$E^=0,M=0$时表示值为0
当$E^`=0,M!=0$时表示$±0.M \cdot 2^{-126}$,比最小值0还小,表示下溢(underflow)或非规格数(Denormal number)
当$E^`=255,M=0$时表示无穷(infinity)
当$E^`=255,M!=0$时比无穷还大,表示上溢(overflow)或无法表示(NaN)
加减乘除
主要考察加减
保护位(guard bits)与截取(truncation)
在计算过程中,会扩展计算位数,称为保护位
一个有效的截取方法应是无偏的(unbiased)
截断(truncation)
保护位的值全部抛弃,不产生影响
冯诺依曼舍入(Von Neumann Rounding)
若保护位中有1,则结果的最小有效位取1
舍入(Rounding)
保护位的最高有效位为1,则
1. 保留位的LSB为0,直接截取
2. 保留位的LSB为1,则给此LSB+1
反之不操作,直接截取
溢出
指数上溢
比如大于127
指数下溢
不如小于-126
尾数溢出
需要左移小数点,指数+1
尾数下溢
保护位的缺陷使得值没有得到保存
加减操作的实现(了解)

定点数和浮点数的比较
定点数:过大的整数无法被表示,非常小的分数也无法表示
浮点数:表示灵活,范围广
习题
(浮点数的表示)
1 . In IEEE754 standard for representing floating-point numbers of 32 bits, the sign of the number is given 1 bit, the exponent of the scale factor is allocated 8 bits, and the mantissa is assigned 23 bits. What is the maximum normalized positive number that 32-bit representation can represent?
$A. +\left(2-2^{-23}\right) × 2^{+127}$
$B. +\left(1-2^{-23}\right) × 2^{+127}$
$C. +\left(2-2^{-23}\right) × 2^{+255}$
$D. 2^{+127-2^{-23}}$
A,最大的正单精度浮点数符号必为0,尾数部分取23个1,故为1.111…1, 指数部分取E=254,实际的指数 $e=127$ ,
$所以是 1.111 … 1 × 2^{+127}=+\left(2-2^{-23}\right) × 2^{+127}$
2 . In single-precision format of IEEE 754 floating point number standard, instead of the signed exponent E, what is the value actually stored in the exponent field?
$A. E=e+255$
$B. E=e+127$
$C. E=e+256$
$D. E=e+128$
B,IEEE 754标准规定单精度浮点数的指数部分占8位, $E=e+(2^{8-1}-1)$
3 . In double-precision format of IEEE 754 floating point number standard, instead of the signed exponent e, what is the value E actually stored in the exponent field?
$A. E=e+2047$
$B. E=e+1023$
$C. E=e+2048$
$D. E=e+1024$
A,IEEE 754标准规定双精度浮点数的指数部分占11位, $E=e+(2^{11-1}-1)$
4 . True or False? A computer must provide at least single-precision representation to conform to the IEEE standard.
True
5 . Using 32-bit IEEE 754 single precision floating point format, show the representation of -0.6875.
$0.6875=0.1011 × 2^{0}=1.011 × 2^{-1}$
$M=0110000000000000000000$
$E=e+127=-1+127=+126, 表示为: 01111110$
所以-0.6875表示为: 1 01111110 01100000000000000000000
(浮点数的计算)
1 . True or False? An overflow of the mantissa field of a floatingpoint number means a real case of overflow.
浮点数的尾数部分溢出并不是真正的溢出,可以通过移位来解决; 而指数部分溢出才是真正的溢出。
2 . Consider a reduced 8-bit IEEE floating-point format, with 1 bit for the sign, 3 bits of the exponent and 4 bits for the mantissa. Note that the mantissa is normalized with an implied 1 to the left of the binary point.
(1) Express $A=2.38$ and $B=1.6$ in this floating-point format.
(2) Write the computation process of A-B and give the result in normalized form. Use Rounding method as needed.
Solution:
$(1) +2.38=+10.0110000=+1.0011 × 2^{1} 0100011 1010$
0 100 0011
$+1.6=+1.1001100=+1.1010\times 2^{0}$
0 011 1010
此处就已经使用了舍入的思想
(2)
①Shift the mantissa of B to the right by one bit position, giving 0.11010 ②Set the exponent of the result to 100.
③Subtract the mantissa of B from the mantissa of A, giving
$\frac{-1.0011 \underline{0}}{0.0110 \underline{0}}$ and set the sign of the result to 0. ④Shift the mantissa to the left by two bit positions. We obtain a result mantissa of 1.1000. So the exponent of the result is 010. The answer is 0 010 1000
注意:各个地方都可能需要舍入,注意操作步骤,指数的结果可以直接加减
存储器系统(注意各元件与方法之间的比较)
基础概念
- 存储器分为内部存储与外部存储,内存包含主存,快速缓存,寄存;外存包括磁盘等
主存组织架构(main mempry organization)
主存由许多个承载位(bit)的单元构成,多个bit(通常数目是固定的)构成了字(word)
字长(wordLength):字中包含的bit数目
为得到具体数据,引入地址。地址反映了字的物理地点
主存访问顺序(注-选择可能)
大字节分配(Big-endian Assignment)
从左到右,从小到大,即MSB在左侧

小字节分配(little-endian assignment)
从右到左,从小到大,即MSB在右侧
主存交互(了解)


结合第一章的MAR,MDR理解
读操作
将特定内存的信息副本加载到CPU
CPU将所需信息的地址加载到MAR并将R/ \overline{W}置为1.
内存将地址中的信息通过data线发送给CPU,并发送MFC信号
当CPU检测到MFC时,将data中的数据加载到MDR
写操作
将CPU给出的信息以覆写的形式写入内存
将地址加载到MAR,将数据加载到MDR,将R/ \overline{W}置为0
当重写完成,内存发送MFC信号
$R/ \overline{W}$:为1时R为1,W为0;为0时R为0,W为1 ;1/0代表是否启用
特征
物理特征(physical types)
半导体(semiconductor):主存
磁(magnetic):磁盘,磁带
光盘(CD):CD,CD-R,CD-RW,DVD
存储(capacity)
字长(word size):一个字所用bit的数量
字量:所使用的字的数量
传输(transfer)
内存:一次读写的数据量常常与字长相等
外存:一般以字块(blocks)的形式传输
访问方式(access methods)
顺序访问(sequential access)
信息以顺序排列在存储器中,访问时需要一个个访问以找到对应的字
例如:磁带
随机访问(random access)
任意内存块可以被随机且直接的访问,访问时间与内存排布无关
例如:RAM
直接访问(direct access)
通过地址直接访问的信息所在的块,然后以顺序访问找到信息
例如:磁盘
时长
访问时长(memory access time)
CPU提供地址并得到数据的时间
对RAM:一次读或写操作的时长
对非RAM:将读写器移动到指定位置的时间
周期时长(memory cycle time)
只用于RAM,表示两个连续的存储器操作开始时刻之间的最小的时间延迟(例如DRAM的重写时长)
传输速率(transfer rate)
数据传入或传出存储单元的速度
易失/不易失(Volatile/Nonvolatile)
易失:断电时,信息会逐渐丢失
不易失:信息一旦记录,就不会变质,直到故意改变。不需要电力来保持
可擦写/不可擦写(Erasable/Non-erasable)
可擦写:存储的信息可以修改
不可擦写:存储的信息不可修改
习题
1 . The memory is organized so that a group of n bits can be stored or retrieved in a single, basic operation. n is called the —-
A. word B. word length C. address D. cell
B
2 . The 32-bit value 0x30A79847 is stored to the location 0x1000. If the system is little endian, the value of the byte —- is stored in address 0x1002.
A. 0x30 B. 0xA7 C. 0x98 D. 0x47
B,MSB在右侧
3 . In a main memory, its word size is 16, the number of word is 8K, what is the capacity of this main memory?
A. 16K×16 B. 16K×8 C. 8K×16 D. 8K×8
C
4 . For random access memory, the time it takes to perform a read or write operation is called —-
A. memory cycle time B. memory hit time C. memory recovery time D. memory access time
A
6 . If you turn off the power to the computer, items stored on —- device will be lost.
A. RAM B. disk C. DVD D. CD-ROM
A
7 . True or False? For internal memory, data are often transferred in much larger units than a word, and these are referred to as blocks.
False
8 . True or False? Memory access time is longer than memory cycle time.
False
9 . What is memory access time? What is memory cycle time? Explain the relationship between them.
Solution: Memory access time is time between presenting the address and getting the valid data. Memory cycle time is time from a memory access to the next memory access. Their relationship is Memory Cycle Time = Memory Access Time + Recovery Time.
RAM(半导体随机存储器)
SRAM(静态存储器)
信息存储在锁存器中

图示的T_1为1,且T_2为0时表示存储的信息为1.(两端自然反号)
读
将字线置为1,使通道打开
通过位线b ,b’读取对应的信息
写
将字线置为1,打开通道
将b置为1,b‘相反——写入1(位线上的信号由S/W产生)
CMOS的实现


视为两个单位的组合,得到了两个反相器
总结
如果电源中断然后恢复,锁存器将进入稳定状态,但不一定是同一个状态
CMOS SRAM 的功耗非常低
SRAM的访问速度极快
SRAM内部组织
一维排列

15个字按行排序,每个的8位按列排序
读
字线(word line) 选择地址后将对应的信息通过S/W,即位线(bit line)输出
写
将输入的信息按地址写入
元件
地址线
输入/输出线
R/W
CS(引脚)
用于在集成芯片存储系统中选择给定的存储器芯片,被激活时,对应的芯片接受R/W信号,反之不响应
地线
供电线
二维排列

图示为1K × 1的存储器芯片,即10条字线和一条位线。字线分为一半,分别用来选择字和位。
加上地线,供电线,R/W,CS则共有15条线
SRAM的优缺点
快,但密度低,成本高
习题
1 . Assume that the capacity of a kind of SRAM chip is 8K×16, so the address lines and data lines of this chip are —- respectively.
A. 8,16 B. 13,16 C. 13,4 D. 8,4
B
2 . Assume that the capacity of a kind of SRAM chip is 32K×32, so the sum of address lines and data lines of this chip is —-
15+32=47
3 . What are the advantage and disadvantage of SRAM?
Advantage: Fast
Disadvantage: Low density, High cost
DRAM(动态随机存储器)

信息被存储在了电容C中,但会逐渐泄露,每次读操作会重写内容,且等到其电荷降低到某个阈值时才能读取内容。
读
字线置为1,晶体管打开
传感放大器检测电荷是否高于某个阈值,若高,则传感器将位线的电压提升至满电压以置为1,于是电容被充满,对应于1;反之位线置为0,电容放电
写
字线置为1
位线置为1时表示高电位,置为0时表示低电位
字线为0时通道关闭,状态短暂维持,需要定期刷新
优点
高密度,低成本
缺点
访问时间长,需要定期刷新,信息容易泄露
异步动态随机存储器(asynchronous DRAM)

RAS(Row Adress strobe),CAS(column Address strobr)
如上图,对于一个32M x 8的动态存储器芯片,首先计算地址线的数量$2^{25}=32M$,故需要25个地址接口,对于行数h与列数d,有h+d=25
如图所示,分配14位用于列地址,分配11位用于行地址。
注:先RAS启用,地址被加载到行地址寄存器,随后CAS被启用,列被加载到列地址加载器
由于上述操作的实现是由RAS和CAS信号控制的,称之为异步动态随机存储器
快速页模式

以此图为例,当读取行地址操作结束时,存储在行中的数据被其元件的放大器提取出来,我们将这些放大器用作寄存器,读取的行地址数据被放入寄存器中,可以支持连续的列操作读取,如上图的R/W circuits&latchs
同步随机存储器(SDRAM)(synchronous DRAM)

所有操作和时钟同步(时序产生了RAS,CAS信号)
通过模式寄存器写入控制信息选择模式
使用缓冲寄存器(R/W锁存器)保存一行的信息,可用来读取连续的行位置,如图中的列地址计数器,在每个时钟上升沿响应,并将递增的列地址对应的数据放到缓冲寄存器上
刷新计数器,同样响应时钟上升沿,用来以读操作连续的刷新位信息
突发传输(burst opration)
内存可以连续快速地传输多个数据单元,而不需要为每个单元单独发送地址和控制信号,从而提高数据传输效率,使用块传输
SDRAM使用模式寄存器(mode register),存储相关信息解决

如时序图
时钟连续两次上升沿之间的时间作为一个周期时间
首先RAS花费一个周期锁存行地址,再使用两个周期激活对应的行。
接下来CAS花费一个周期锁存列地址,再花费一个周期将数据放到数据线上,并以时钟上升沿为准,地址递增从而使连续的信息传送到数据线上。脉冲长度(pulse length) 表示一次操作的最大自增传输次数。因此,一旦一次操作的连续读或写次数超过脉冲长度,就需要重新寻址。
延迟(latency)
对内存而言,是指请求数据传输到实际开始数据传输的时间间隔
对块传输中,延迟指传输块的第一个字所用的时间,是评估存储器传输性能的开销时间,在上述例子中,这个时间是5个周期
带宽(bandwidth)
每秒传输的字节或位的数量,可以理解为总线的传输速度与其宽度的乘积。与延迟共同决定了存储器的性能
DDR SDRAM
即双倍数据速率SDRAM,在时钟的上下沿都传输数据。对于常突发传输,其带宽基本翻倍
DRAM的优劣
优点:高密度(density),低的成本
缺点:存储器访问时间长,易泄露,需要定时刷新
习题
1 . Comparing to SRAM, the main advantage of DRAM is
A. high speed B. non-volatile stored data C. high density D. easily controlled
C,此处选项可以仔细看看
2 . What are advantages and disadvantages of DRAM?
Advantages: High density, low cost
Disadvantages:Longer memory access time;Leaky, needs to be refreshed.
3 . 某一动态RAM芯片,容量为64K×1,除电源线、接地线和刷新线外,该芯片 的最少引脚数目应为多少?
64K=216,由于地址线引脚只引出一半,因此地址线引脚数为8。数据线引脚数为1 (有的芯 片数据输入线与数据输出线是分开的,则数据线引脚数就为2)。它有R/W信号,而没有CS 信号。它有行地址选通信号RAS和列地址选通信号CAS。综上所述,除电源线、接地线和 刷新线外,该芯片的最少引脚数目应为12。
这道题bug很多,比如是否需要考虑时序及其引脚
大容量存储器结构(注-大题)
静态存储器系统
速度快,成本高,位密度低
位扩展法
当芯片的每个存储单元的位数小于存储区字长时,横向扩展
如用 1 M × 1 位存储芯片组成 1 M × 8 位的存储器
需要8块1M x1位的芯片,横向放置,每片输出一位,合起来就是8位

8块芯片共用一个地址线,一次输出8位
字扩展法
芯片的容量小于存储器容量,纵向扩展
如用 256 K × 8 位芯片组成 1 M × 8 的存储器
首先得到地址线,再得到选片线,选片信号一般需要经过译码器来指向不同的芯片,而地址线则作用于被选中的芯片

注意总线的画法
图示为横向的扩展,但其实现无关紧要,稍后给出既需要字扩展又需要位扩展的默认排列
字位同时扩展
如用 512K × 8 位的存储器芯片组成 2M × 32 位的存储器

图示为应试步骤,注意$\frac{2\times 1024}{32}\times \frac{32}{8}=4\times 4=16$的格式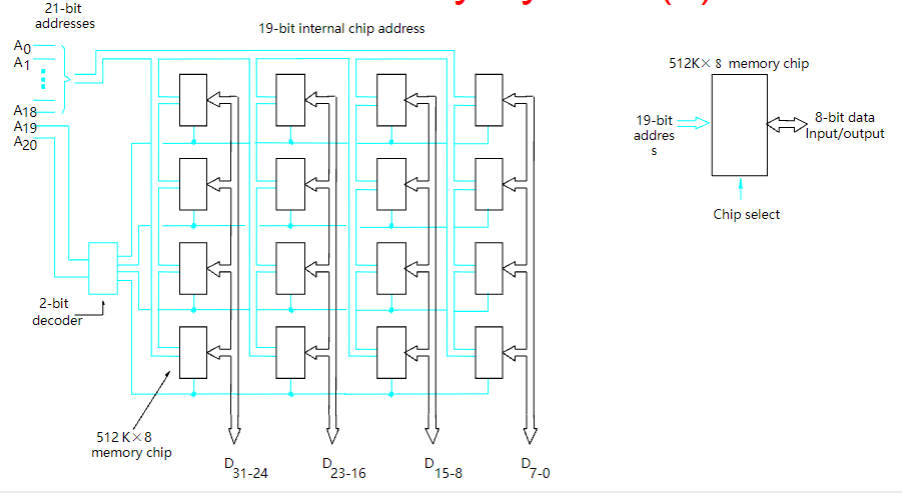
注意输入/输出总线的箭头是双向的,注意地址总线和片选线要连接到每个元件上,注意要给出单个元件的图例,注意信号从0开始排列
按字节与按字编址
唯一的不同在于容量的计算以及输出总线的接口数。
按字节的意思是一条地址数据对应着8bit=1Byte的数据量
而按字的意思是一条地址数据对应着其他的位的数据量,一般取决于题目
动态存储器系统(了解)
位密度高,成本低,用电少,集成方式与静态几乎一致
SIMM单列直插存储器模块
基于DRAM,适用于老系统
SIMM可以是单面的,也可以是双面的
DIMM双列直插存储器模块
目前DIMM是内存分装的标准模式
存储控制器
为异步DRAM提供周期刷新的指令,或为其他交互提供指令操作
刷新开销(refresh overhead)
当内部正在刷新时,动态随机存储器不会响应读写的请求
静态存储器(SRAM)常用来构成cache或寄存器等,而动态随机存储器(DRAM)常用来构成内存(主存)。
习题
1 . CPU的地址总线16根 (A15~A0,A0为低位),双向数据总线8根 (D7 ~ D0),控制总线中与主存有关的信号有MREQ (允许访存,低电平有效), $R / \overline{W}$ 高电平为读命令,低电平为写命令) 主存地址空间分配如下: $0000_{H} ~ 3 FFF_{H}$ 为系统程序区,由只读存储芯片组成;4000H~ $4 FFF_{H}$ 为系统程序工作区,由SRAM组成; $6000_{H} ~ 9 FFF_{H}$ 为用户程序区,也由SRAM组成。 按字节编址。现有如下存储器芯片:
– EPROM:8K×8位 (控制端仅有 CS) SRAM:16K×1位,2K×8位,4K×8位,8K×8位 请从上述芯片中选择适当芯片设计该计算机主存储器,画出主存储器逻辑框图,注意画出选 片逻辑(可选用门电路及3:8译码器74LS138)与CPU的连接,说明选哪些存储器芯片及选多少片。
如下图所示,题目要求输出只能为8位,不够的需要自己平凑;还要求了总线数量,我们需要对地址空间分组,如下图:
由此,前三位用来产生片选信号,而对于4000到4FFF区域的片选信号,由于会与001代表的3起头的地址空间重合,如使用其不需要的地址线A14平凑出一个新的片选信号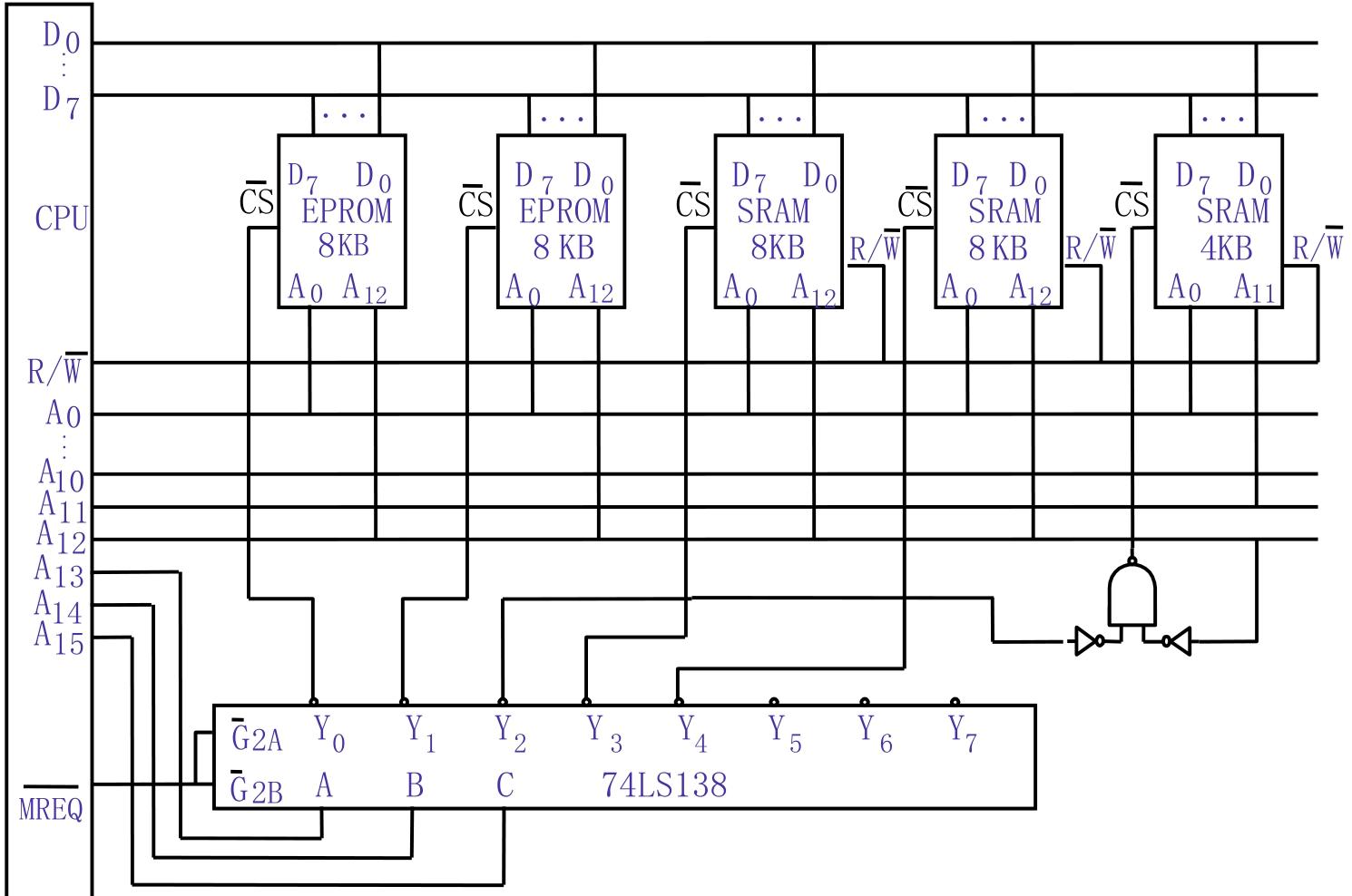
2 . Consider a 16M×128 memory built by using 512K×16 memory chips. How many rows of memory chips are needed?
A. 8 B. 16 C. 32 D. 64
C,16 M / 512 K=32
3 . Consider a 64M×16 memory built by using 512K×8 memory chips. How many memory chips are needed?
A. 32 B. 64 C. 128 D. 256
C
$\left(64 M^{} 16\right) /\left(512 K^{} 8\right)=256$
4 . Consider a memory can be accessed with 20-bit address. Its word length is 64-bit and it is word-addressable. Assume that we use 256K×8bit SRAM chip to constitute this memory.
(1)How many bytes can this memory store?
$2^{20} 64 / 8 B=1 M 8 B=8 MB$
(2)How many SRAM chips do we need?
$8 MB /\left(256 K^{} 8 / 8 B\right)=8 MB / 256 KB=32 片$
注:先对齐输出位
(3)How many address pins do we need for chip select? Why? 因为每片芯片内部有18位地址 (对应于256K个存储单元),所以,20位的地址中,低18位地 址直接接芯片的18位地址端,高2位地址通过2:4译码器作芯片选择。
5 . Assume that there are two types of static memory chips: 128K×8 bit (total 4 chips) and 512K×4 bit (total 2 chips). Please use these memory chips to implement a 512K×16 bit memory. Draw the figure of the memory organization.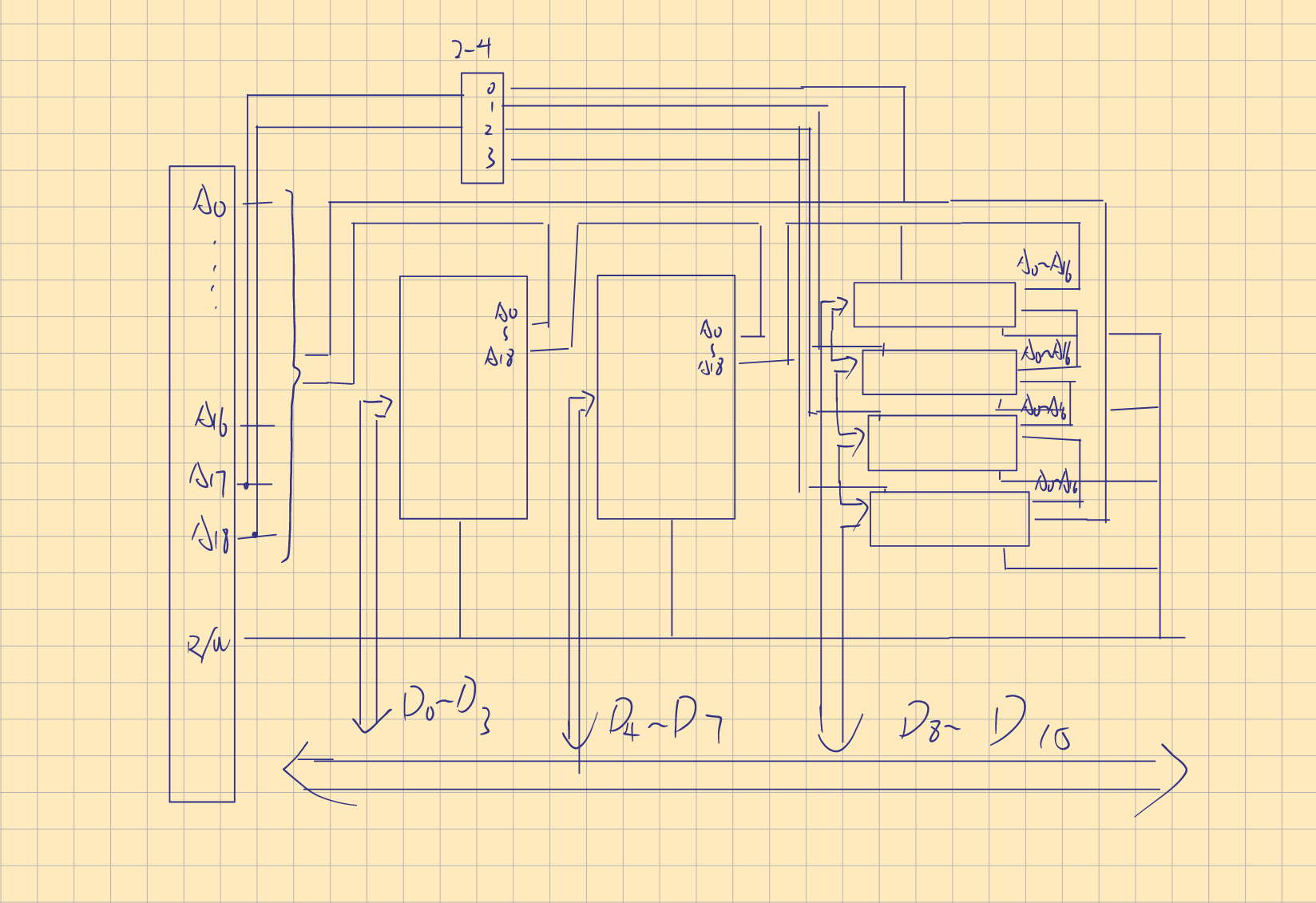
*注意:CPU的接口数为横向看去的最大容量对应的二进制值,不同块的片选则需要看各个分区纵向看去的块数对应的二进制值
只读存储器
存储空间很更大,速度更慢,价格更低。
相比起上文提及的两个随机存储器,只读存储器是非易失的。由于其只读的限制,写入操作需要特殊的实现。
内存层次
ROM(只读存储器)
只能在生产时写入数据的存储器称为只读存储器(或ROM),如下图所示。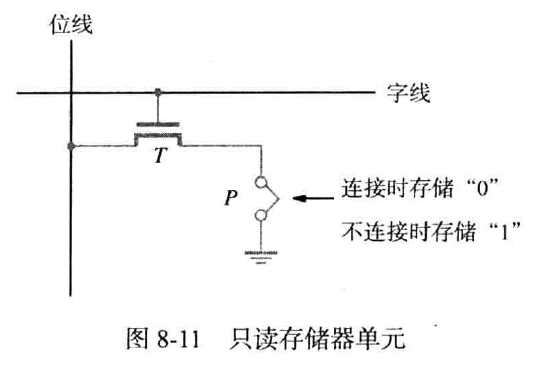
ROM在生产时根据一个决定存入信息模式的掩码决定存储单元接地与否。晶体管在被字线激活时,若是接地,则位线为置为0,反之为1。
由于未设置电容,读取后没有后续操作,且接地与否无法通过电路信号改变。
PROM(可编程只读存储器)
不同于ROM,PROM将唯一一次的写入交给用户,用户通过高电流脉冲将存储单元中的熔丝熔断,使其置为1,其他未操作的单元保持原值0。综上,PROM支持一次用户的编程行为。
EPROM(可擦除可编程只读存储器)
其结构相似于ROM,但是p点的电路替换为特殊的晶体管,向内注入电荷以形成通路,反之将其暴露在紫外线下以擦除数据。这意味着必须通过物理手段擦除数据,且擦除范围极大,没有办法对单存储单元生效,暴露在紫外线时,全部的信息都会被擦除。
EEPROM(电可擦除可编程只读存储器)
需要不同的电压来实现擦除,写入,读取,其他的都是有优点,可以对点式的擦除数据。
闪存
密度更高,只需要单一的电压就能实现擦除,读,写。功耗更低
闪存卡
闪存驱动器
相比于硬盘存储驱动器,容量较小,且成本高,但访问速度快,响应时间短,
直接存储访问(DMA)
由于在CPU控制下的主存与I/O之间的信息交互需要大量开销,故提供一个专门的部件管理传输过程,称为直接存储器访问(DMA),此部件称为DMA控制器。
CPU将控制信息传递给DMA后就撒手不管了,直到DMA发送完成信号。详细见下图: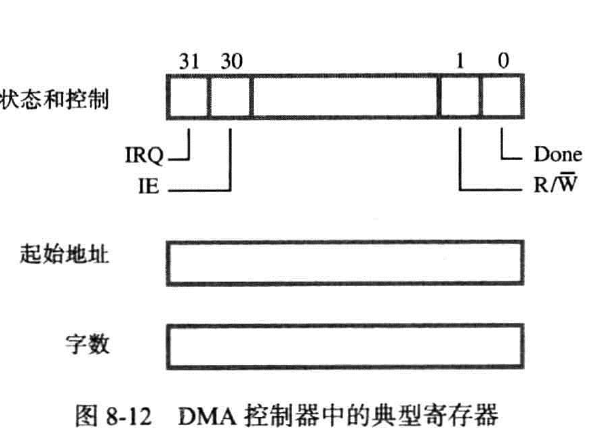
当一块数据从主存传送到另一个磁盘时,CPU访问DMA中的寄存器,将地址和字数信息写入对应的区块,此后DMA将独立执行指定的操作。当传输完毕后,DMA将Done线记录和传输信息。
存储器层次结构(Memory Hierarchy)(注-)
由于一个存储器无法做到内存又大,访问速度又快,价格又便宜,密度又大,耗电又低,故尝试把所有的存储器视为一个集合的存储器,称之为存储器层次结构,让他有快速而大的特性,他具有多个存储级别,并确保大部分数据处理器需求保持在 FAST(er) 级别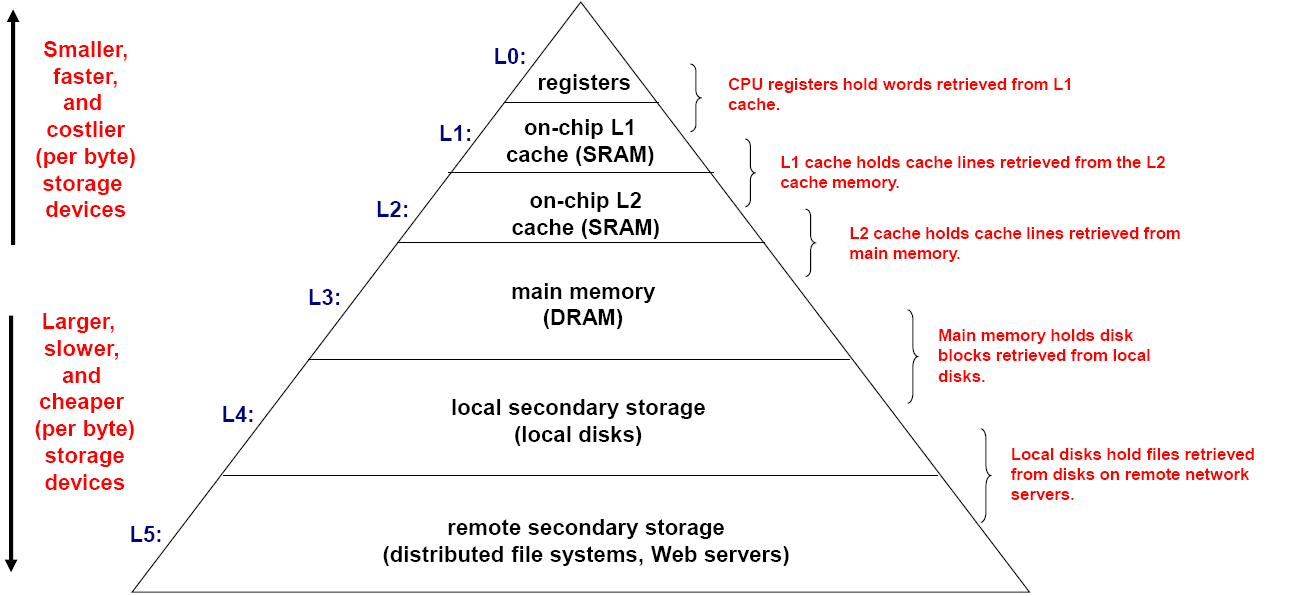
主高速缓存放置在CPU内核内部,称之为一级(L1)高速缓存,一个更大的速度稍慢的辅助高速缓存放置在L1和其他存储器之间(一般在CPU内核外部),称之为二级(L2)高速缓存,也放置在CPU内部。
每一级存储器的数据都可来自于上一级。
其核心就是缓冲区
buffer(缓冲区)
作为一个更大更慢的存储器的子集存储器
对于每一级K,都可作为上一级K+1的缓冲区
所有的数据最终都存储在最后一级的存储设备内
数据在相邻的两级之间交换
习题
1 . A memory hierarchy —-
A. limits programs’ size but allows them to execute more quickly
B. is a way of structuring memory allocation decisions
C. takes advantage of the speed of SRAM and the capacity of disk
D. makes programs execute more slowly but allows them to be bigger
C
高速缓存(cache)(注-大题)
由层次结构,cache是一个速度极快但大小极小的存储器,他位于CPU及主存之间。术语上有高速缓存块(cache block) 以及高速缓存行(cache line/entries)
处理器发送读指令时,存储器中的信息加入cache,随后的交互都从cache中获得。当cache存满时,要求必须在cache中腾出一块空间以加入新增的信息。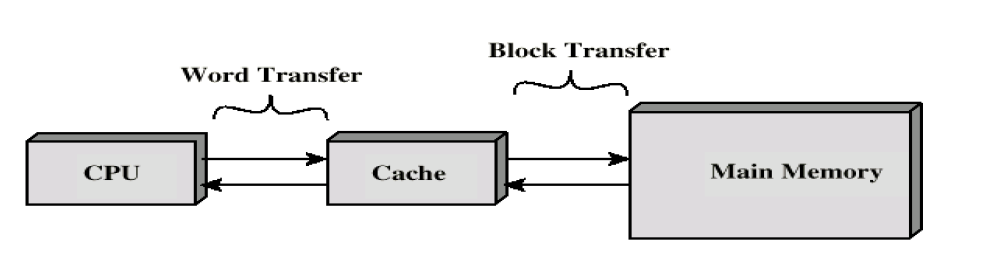
在缓存中,数据以列(line) 的形式存储,一般一列存储一个块
局部性(locality of refence)
时间局部性
最经执行的指令可能再次执行,加入cache;
空间局部性
最近执行的指令附近的指令也可能再次被执行,加入cache;
映射(mapping)
映射关系:
- 决定块被放置到cache的哪里
- 将指向主存的地址,转而指向cache,而不是直接以此访问cache
直接映射(direct mapping)
主存块的编码模128后得到的值作为cache的地址,但128,256等的块会发生冲突,即使此时cache未满。
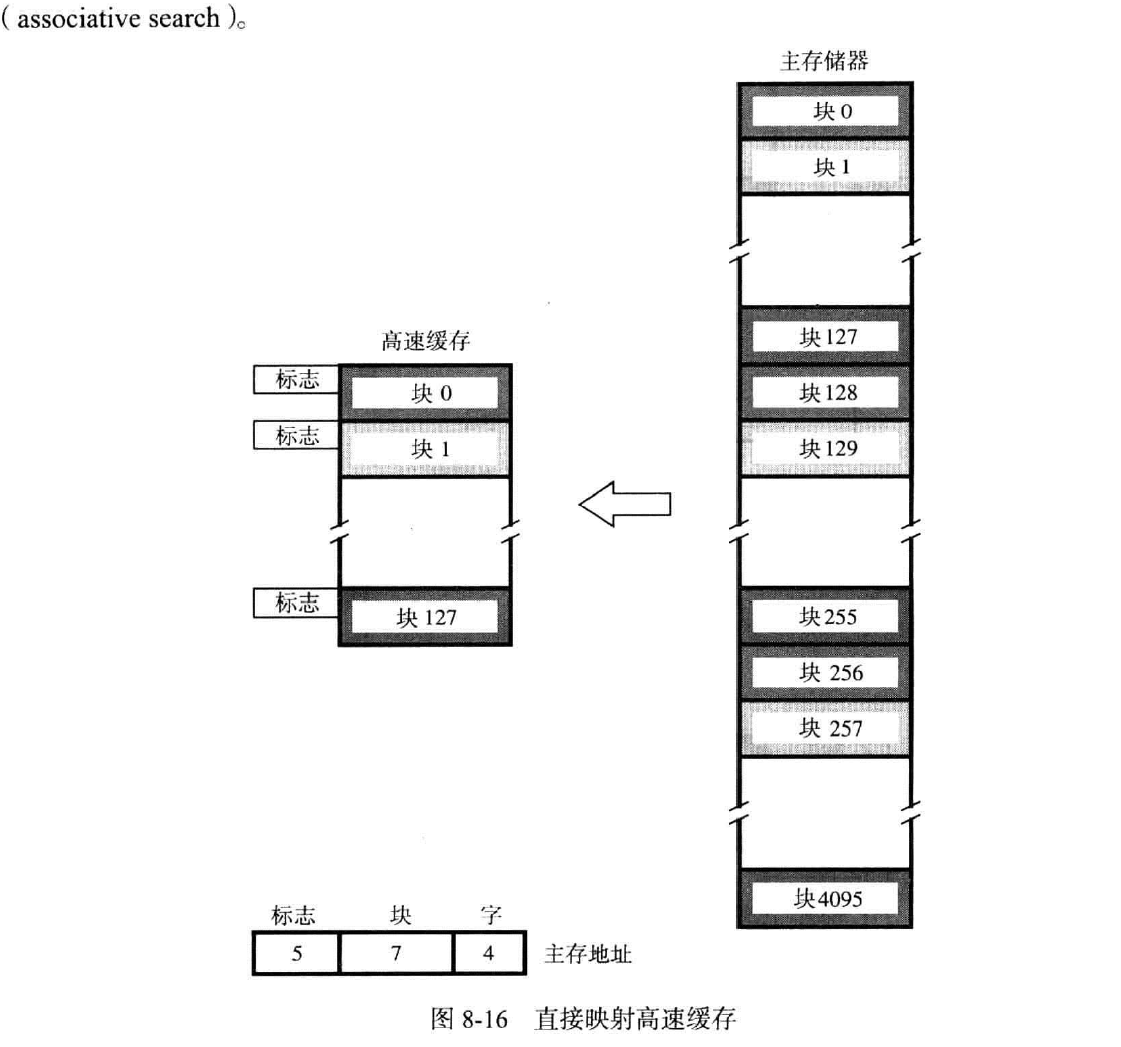
cache中,一行就是一块。
在此中,作为访问主存中某个字的地址(共16位),分为三个部分:标志,块,字。
标志(Tag,t):用来写入高速缓存中,且用来决定是哪个能取模到此高速缓存地址的主存块被使用(一般共有32个),还用来比较需要的字是否在此处的cache中
块(Block.r):用来决定使用高速缓存的哪个部位(取模操作)
字(Word,w):从16位的块中选择一个CPU需要的字
综上,块中的二进制转十进制后取模(取模的数取决于cache能存储多少块),标志决定是哪个同模的块被取,字决定取哪个字。
0.9以上的高速缓存命中率对高性能计算机至关重要
可以依靠下图理解
t中存储的是商,r中存储的是模
下面给出例子示例:考虑一个由 128 行组成的缓存,每行16个词。主存储器有 64K 字。假设
1.主存储器可通过 16 位地址寻址。
总主内存块数=64K/16=4K=4096
故有s=12;
每块有16个字,故需要4位寻字,即为w
128行表示s中留出7位在cache中寻块,即为r
12-7=5,即为t
评价
优势:简单,易于实施,便宜
缺点:块的位置固定,如果程序访问映射到同一行的 2 个块反复出现,缓存未命中率非常高
相联映射(Associative Mapping)
从CPU接收到地址后,到cache中检索,cache中每个块维护一个12位的标志位(是上述的16位地址去除4位字后的结果),若检索到一样的标志,那么代表找到对应的块,再对应到字。
若未找到,则扔掉某个块(替换算法)(在cache已满时),再将12位的信息写入标志位中,再将块写入。
可以避免一个个检索带来的长时间消耗,使用并行检索(相联检索)。
是有两个组分:t和w
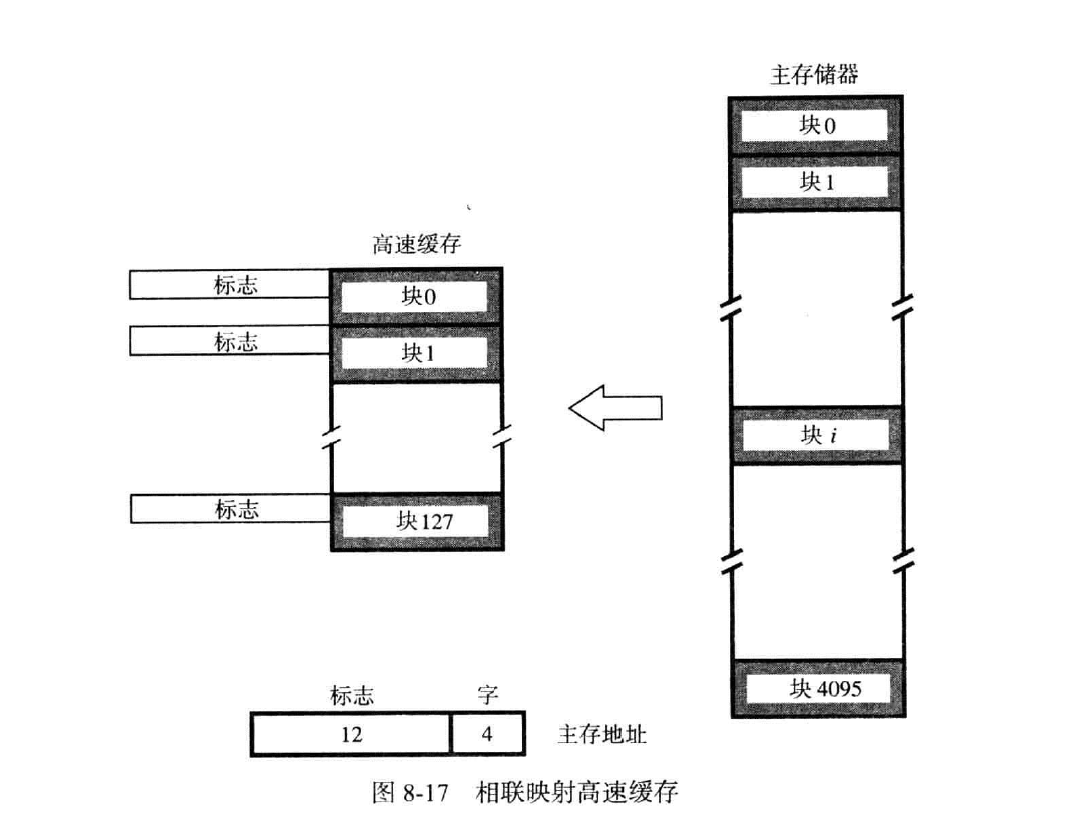
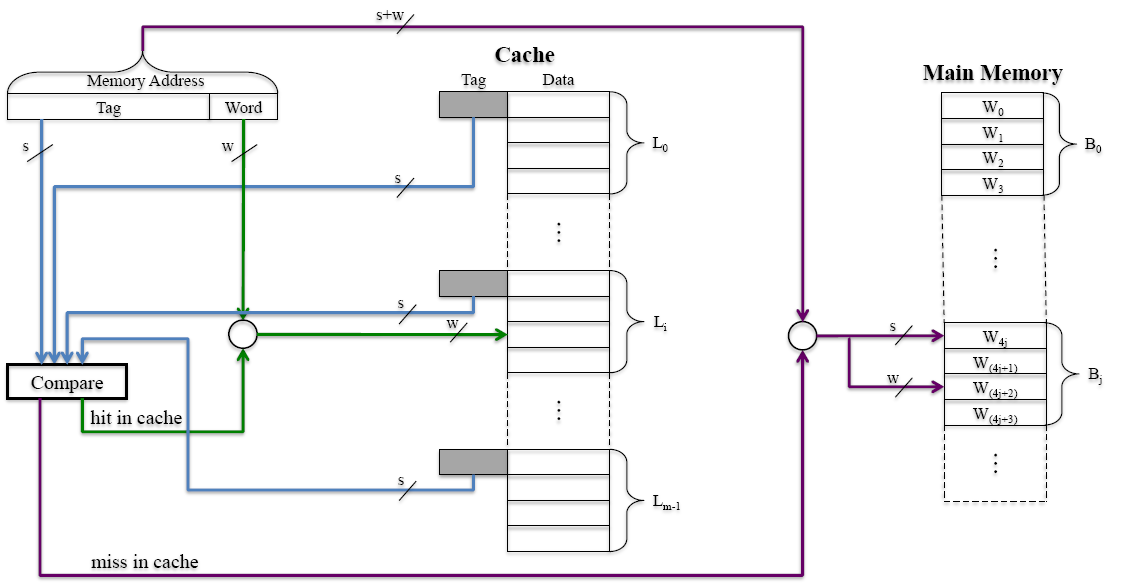
如同上一个例子,12位的s填入t,w用来寻字
评判
优势:它为选择缓存提供了完全的自由,放置内存块的位置。
缺点:检查所有标签所需的复杂电路。
组相联映射(set associative mapping)
是直接映射和相联映射的结合,cache被分为大小相同的组(d),每组存放一定数量的块(k),一个主存的块被映射到特定组(直接映射)的任意行(相联映射)。
由此,我们对主存的块数j取模于组数v。
二进制的k转十进制后取模(取模的数取决于cache能存储多少块)得到s,标志决定是哪个同模的块被取,字决定取哪个字。也就是说,主存中的块的编码决定了要求的字所在的块被存放到cache的哪里,额外的字线会决定取块中的哪个字;而s包含组数(d),以及标志位s-d。之后,放入组的块进行相联映射,比较的是标志位。
如下图所示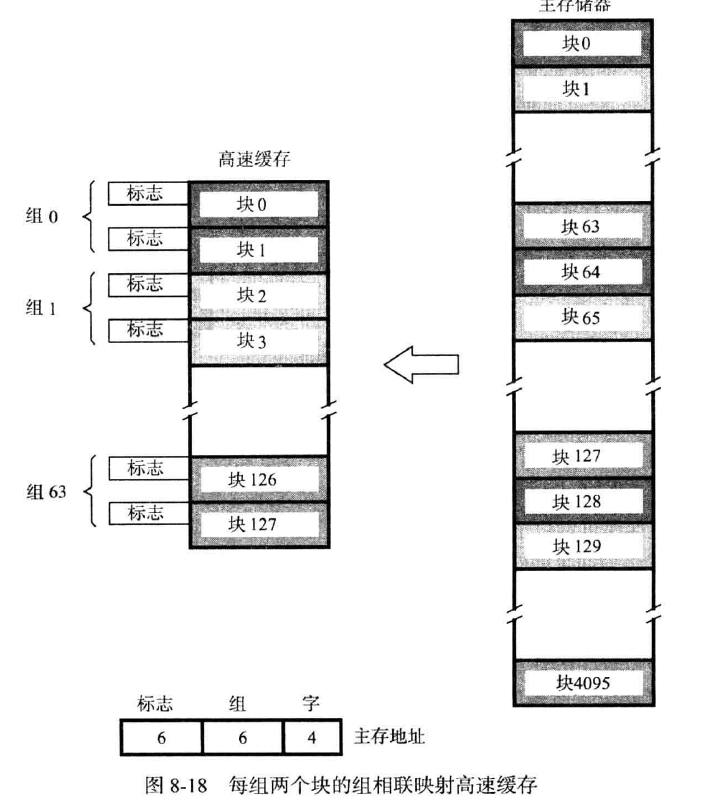
一般的,当k取2时,称之为2路组相联高速缓存。
例如:对直接映射的例子而言,我们分配了12作为s的值,选取组相联高速缓存,则有组数d=64,s-d=6;
评价
优势:解决了直接映射重复弹出cache与加入cache的问题,开销比相联映射低
弊:仍然需要并行比较,比较成本较高。硬件成本比直接映射高,比相联低
过时(out data)数据
cache还维护一个有效位(vaild bit),防止过时的数据被利用。当该位为0时,表示此值无效,访问在此发生时,表示miss;反之有效。
当cache从断电恢复时,其中的所有有效位为0,当一个块被装入cache中时,其有效位置为1。如果需要修改的块在cache中,则其有效位为0。只有当有效位为1时,才能从中提取数据,防止提取到未修改的落时的数据。
高速缓存一致性
当主存中的数据需要传回磁盘中的时候,需要将cache中的新的数据写回主存中。在使用写回的系统中,需要如此的方法来保持主存与磁盘数据的有效性与一致性。
替换算法(replacement algorithm)
即将块弹出cache中的选择算法。替换算法对直接映射没有意义,因为直接映射必须替换唯一的位置
LRU(最近最少)
覆盖的块中最少被访问次数的块将被移除。cache为每个块添加一个2位的技术区域,每次访问发生时,被访问的块的技术区域置为0,反之+1。当存在一个值为3的块时,就将其移除。
FIFO
先进先出
随机
依靠随机数排除块,有时比LRU有效
(注)例子
现在我们假设要执行一个算法,这个算法需要主存,cache的参与:
我们将这个算法拆开来SUM:=0
for j:=0 to 9 do
SUM:=SUM+A(0,j)
end
AVG:=SUM/10
for i:=9 down 0 do
A(o,i):=A(0,i)/AVG
end
现在来看一眼主存配置和cache配置
我们假设主存中每个块只存储了一个字(你可以理解为按块寻址)(因为我们的算法只需要一个字的参与,为了方便模拟块的进入与弹出,块中只存放一个字),块的阵列为4 $\times$ 10,如右侧内容所示,但此处排开了,依顺序为00,10,20,30,01,11,21,31,02,,,。cache有8块,同样每个块放置一个字。
直接映射
因为cache有8块,故留出3位以取模
如下图所示(原图太大,此表格中一列表示循环步数+2)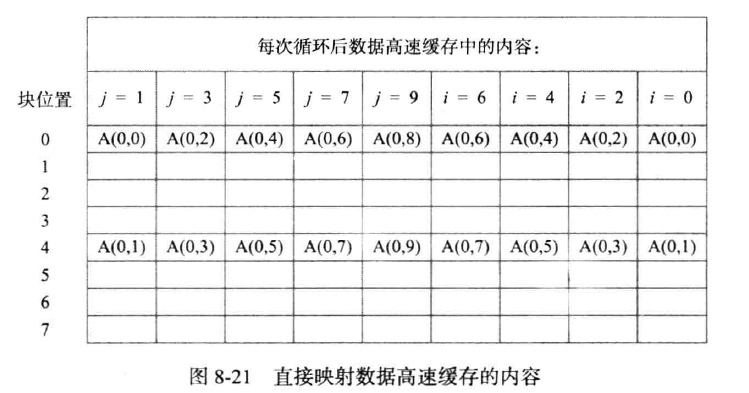
根据伪代码给出的步骤,要将值加入SUM,则访问字所在的块A(0,0),此块加入cache,地址为000(二进制换算为0);再访问A(0,1),地址为100(二进制换算为4);再访问A(0,2),地址为000,且标识符与A(0,0)不同,故弹出A(0,0),加入A(0,2),,,此后可自由推断,若标识符合,则不弹出,反之弹出。
相联映射
地址全取
如下图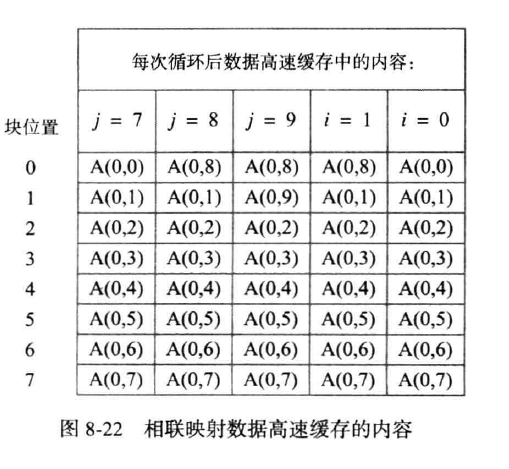
按相联映射的规则,取前图的标识码,依次取。当加入A(0,8)时,由于cache已满,弹出cache中最久未使用且最近的A(0,0)弹出,并将A(0,8)加入,到i=1时,由于A(0,9)是最久未被使用的,故替换,此后同理。此处cache的计数位应为三位。
组相联映射
如下图,假设使用4路组相联高速缓存,故cache中只有2组,留最后一位为组别,前15位为标识位。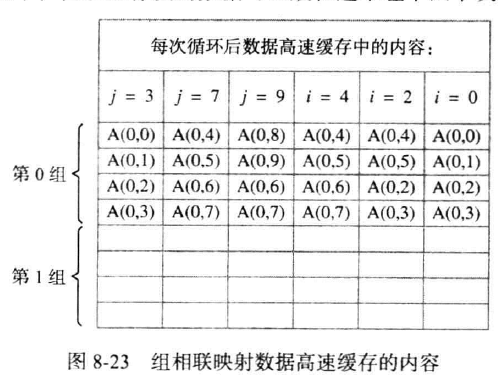
由于0打头的块的地址的最后一位都是0,故使用不了第二组了
习题
1 . By —- mapping technique, a main memory block can be placed into any cache block position.
A. direct B. associative C. set associative D. sequential
B
2 . If a cache has a capacity of 16KB and a line length of 128 bytes, how many sets does the cache have if it is 2-way, 4-way, or 8-way set associative?
A
3 . A set-associative cache consists of a total of 64 blocks divided into 4-block sets. The main memory contains 4096 blocks, each consisting of 128 words. How many bits are there in a main memory address?
A. 21 B. 24 C. 19 D. 32
C
4 . A set-associative cache consists of a total of 64 blocks divided into 4-block sets. The main memory contains 4096 blocks, each consisting of 128 words. How many bits are there in each of the TAG, SET, and WORD fields?
A. 2,5,12 B. 12,2,5 C. 4,8,7 D. 8,4,7
D
5 . What are advantages and disadvantages of direct mapping?
Its advantages are: (1) Simple, easy to implement (2) Inexpensive
Its disadvantage is: fixed location for given block
6 . What are advantage and disadvantage of associative mapping?
Its advantage is that it gives complete freedom in choosing the cache location in which to place the memory blocks.
Its disadvantage is that it requires complex circuitry to examine the tags of all cache blocks in parallel.
高速缓存命中(Hit)
CPU本身不知道cache的存在,他只会发送信号,而cache拿取到信号后则会进行判断
读或写命中(read or write hit)
当读写操作的对象块存储在cache中时,直接在cache中读写,这称之为读或写命中。
读操作
上文提到,读的字的块在cache中时,直接在cache中读取。
写操作
若块不在cache中,则将块加入cache。
直接写(write through)
写操作同步于cache和主存之间。
写回(write back)
写操作只在cache中进行,并使用特殊的位表示信息是已更新且可用的,如修改位(dirty)。当这个块移出cache中时,再对主存修改。
直接写和写回的比较
直接写:
- 优点
- 使得数据在缓存和主存间始终保持一致,无论何时都能在两处读取到同样正确的信息
- 缺点
- 所有的写操作都要访问主存
- 拖延CPU处理其他信息
写回:
- 优点
- 快于直接写,时间花费更少
- 多次对缓存中的数据修改,但只需要最后一次修改主存的数据
- 缺点
- 主存中对应的数据是过时的,不可使用
- 需要在缓存中添加一位dirty,表示是否是修改的
读或写失效(Miss)
读操作
对一个不在cache中字进行读操作,会造成一次读失效,然后包含字的块从主存拷贝到高速缓存中,再把字传入CPU。
直接装入(早重启)(load through/realy restart):字从主存中取出后直接送往CPU再装入缓存。
写操作
不写分配(No-Write Allocate)
直接在主存中修改数据写分配(write Allocate)
块先加入缓存,再在缓存中修改数据命中率(hit rate)和失效开效(miss penalty)
cache提高性能的程度依赖于所请求的指令和数据在cache中找到的频繁程度。
由于CPU不知道cache的存在,而在存储器层次结构中每 $k_{i-1}$层都可以视为上一层的缓冲池,故可以把整个存储器层次结构视为一个存储器。命中
即所需的数据和指令能在cache中找到,未找到则称之为失效。失效开销
失效发生时,数据以及指令需要从低速存储器装入高速存储器,此额外的时间称之为性能开销,在这段时间内CPU暂停以等待数据,而发生失效时CPU等待数据的总时间称为失效开销。得到CPU的平均访问时间如上。其中,C是访问缓存需要的时间,M是访问主存需要的时间。
选取直接装入法或先写入cache再装入CPU会对M产生影响。例子
若有一个计算机,访问cache需要时间r,访问主存需要时间10r;访问cache失效时转去访问主存,此时传输第一个字需要10r,随后的一块中的7个字需要7r,再访问cache需要1r。
故有失效开销:M=19r
假设一个程序有100条指令与数据需要传输,命中率是0.95,则有无cache与有cache的时间对比由此,发生失效时计算失效开销,否则按访问cache计算。多级缓存
正如存储器结构涉及的那样,在CPU上添加两个一级( $L_1$ )高速缓存MDR,MAR,分别负责数据以及地址的传输。在某些高性能处理器上,还会存在一个二级($L_2$)高速缓存,其速度比一级慢,但其容量大于一级。
相比于此节涉及的CPU和主存之间的统一缓存,有以下优势评价
使得访问的随机性更小,也更有聚集性;相比于统一的缓存,访问速度更快
处理器芯片上的高速缓存
这里把二级缓存视为一个较小的主存,那么二级缓存的平均访问时间就是一级缓存的失效开销。假设指令与数据的命中率一致,则:
此中,$h_1$表示一级缓存的命中率,$C_1$表示一级缓存的信息访问时间;$h_2$表示二级缓存的命中率,$C_2$表示二级缓存的信息访问时间;$M$表示二级缓存的失效开销;$h_2C_2+(1-h_2)M$是二级缓存的平均访问时间,也是一级缓存的失效开销。
一级缓存的失效率是$1-h_1$,在此基础上,二级缓存的失效率是$(1-h_1)(1-h_2)$,很小。
其他改进(没讲)
写缓冲区(write buffer)
如同主存与磁盘或其他I/O设备之间的控制器DMA,在CPU与主存间也存在一个能提高CPU速度的元件:写缓冲区。
使用直接写时,写的数据内容存入写缓冲区,由于读操作必须先行,CPU需要等待读操作完成才能进行下一个操作,故一般需要与缓冲区中的写数据的主存地址与读比较,有则读取缓冲区中的数据,反之继续读,全部的读操作完成后才开始写操作。
使用写回时,cache替换的块同样需要写操作,可以把这个块装入缓冲区,其他操作同上。
预取(prefetch)
上面提过,当读操作发出时,必须等待其操作完成,此间CPU被暂停。为了避免暂停过程,提出预取:在数据被需要前,就把数据添加到cache中,可以用软件或硬件实现。但后果是,当预取操作后的读失效替换了预取的块时,开销就无故增加了。
无锁定高速缓存
使用预取时若与其他操作在cache上发生冲突,代表响应失效,这时cache被锁定,无锁定高速缓存可以在响应失效时继续访问。
习题
1 . The effectiveness of the cache mechanism is based on a property of computer programs called —-
A. parallelism B. locality of reference C. make the common case fast D. forwarding
B,局部性原理,注意题意是缓存
2 . Which of the following manages the transfer of data between the cache and main memory?
A. compiler B. registry C. operating system D. hardware
D,Cache-主存系统完全由硬件管理
3 . If a cache has 64-byte cache lines, it takes —- cycles to fetch a cache line if the main memory takes 20 cycles to respond to each memory request and returns 2 bytes of data in response to each request.
A. 128 B. 320 C. 640 D. 256
C,这题出的莫名其妙
4 . In cache system, when a block is to be overwritten, it is sensible to overwrite the one that has gone the longest time without being referenced. This technique is called the —- replacement algorithm.
A. FIFO B. Random C. LFU D. LRU
D
5 . True or False? In a direct-mapped cache, it is sensible to use Random replacement policy when a line must be evicted from the cache to make room for incoming data.
In direct-mapped caches, there is no choice about which line to evict, since the incoming line can only be placed in one location in the cache.
6 . True or False? For a Write operation, the cache location and the main memory are updated simultaneously. This technique is called the write-through protocol.
T
7 . What are advantages and disadvantages of write through policy?
Advantage: Keeps cache main memory consistent at the same time.
Disadvantages:
(1) All writes require main memory access (bus transaction).
(2) Slows down the system - If the there is another read request for main memory due to miss in cache, the read request has to wait until the earlier write was serviced.
8 . What are advantages and disadvantages of write back policy?
虚拟存储器(注)
当CPU的可寻址空间大于主存时,一般的主存无法满足CPU的要求,这时就需要虚拟存储器。CPU正在需要的部分存放在主存,其余放置在虚拟存储器(一般是辅助存储器,如磁盘)。当CPU引用了一个数据或指令时,会发出虚拟地址(也叫虚拟地址),存储器管理部件(MMU)(MMU一般放置在CPU中) 会比较此虚拟地址对应的数据是否在主存中,若在主存中,则转换为物理地址;反之,则通知CPU把数据从磁盘传输到主存中。
注:虚拟存储器指虚拟主存,是一种抽象概念,而不是特指磁盘。
如下图所示: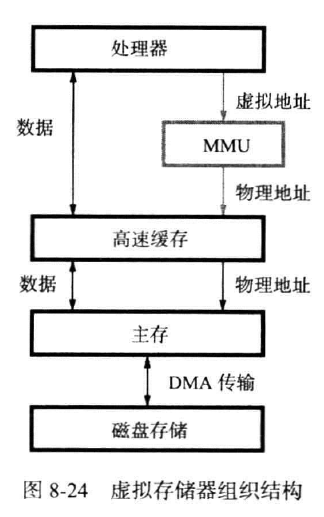
覆盖(Overlaying)
是一种用于内存管理的技术,通常在物理内存有限时使用。程序被分成若干部分(称为“段”或“覆盖区”),并且在程序执行时,根据需要动态加载某些段,而不是将整个程序一次性加载到内存中。
使用了局部性原理
通过覆盖技术,程序员可以在有限的内存资源下运行大规模程序,但手动管理这些段的调度和加载过程非常繁琐,因此该方法在现代系统中不常用。
地址转换
当MMU确定需要把数据从硬盘传输到主存时,把硬盘中的数据规划为页(与块对应),页的大小一般为2K到16K个字节。
CPU产生的虚拟地址,被解释为虚拟页号(virtual page number) 和偏移值(offset)(用来在大小为page size的空间中找寻对应的字节或字)。还在主存维护了一个页表(page table),用来指示页所在的主存地址(从虚存映射)(也可以称为物理页号PPN),此外,还有一个页表基址寄存器(page table base register),用来存储页表的起始地址;主存按页的大小分划为页帧(page frame)。
页表存储了页表项(page table entry),包含:
- 页帧码(page frame number),用于找到页帧的地址,或一个指向磁盘的地址,表示虚拟页目前不在主存,而是磁盘
- 有效位:表示该页是否有效
- 修改位(modify bit):表示该页是否被使用过
- 使用位(use bit):表示该页最近是否被用过,用来评判活跃以便替换
- 访问控制位(Accress Control bit):表示读写等操作的控制位
根据给出的虚拟页号和页表基址寄存器得到映射的页表的起始地点,可以直接按索引找到这个页在页表中的位置(直接映射:虚拟页号到实际页号),再通过这个位置拿到页在主存中的地址(页帧),然后根据偏移值拿到对应页帧中需要的那一个字(或字节)。
如下图: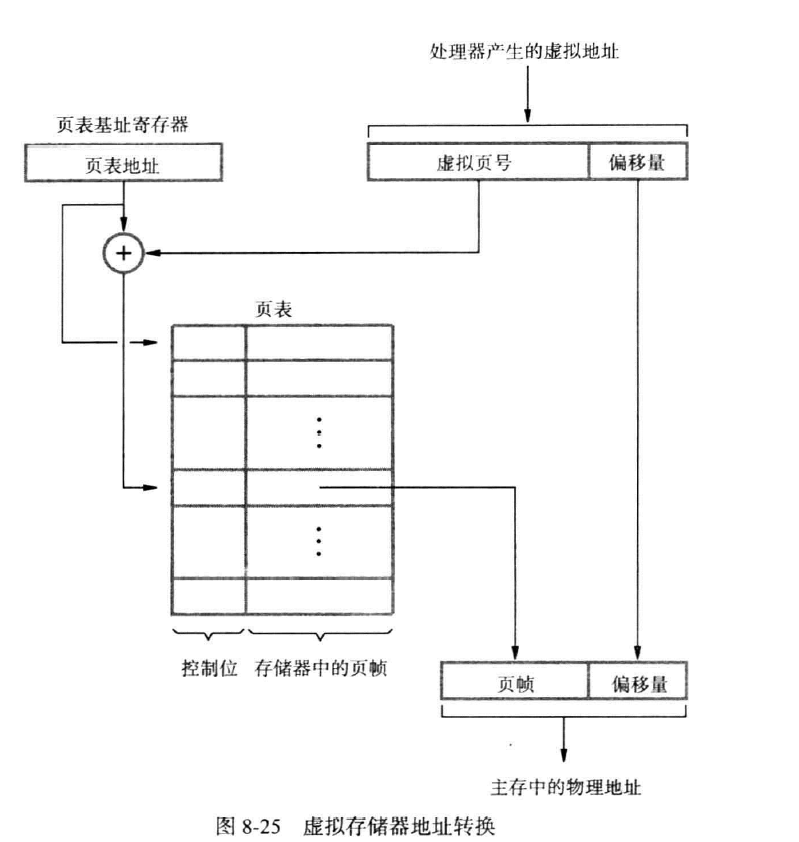
注:页表中不存储页号,因为可以按虚拟地址直接访问。转换监视缓冲区(TLB)
MMU中存在转换监视缓冲区,用来存放那些最近被使用的页的表项(因为页表太大而存放在主存中)(相联映射:虚拟页号到TLB的相联)。
TLB的状态信息需要与页表时刻保持一致,当操作系统修改页表中的内容时,同把TLB中对应的项置为无效。
如下图: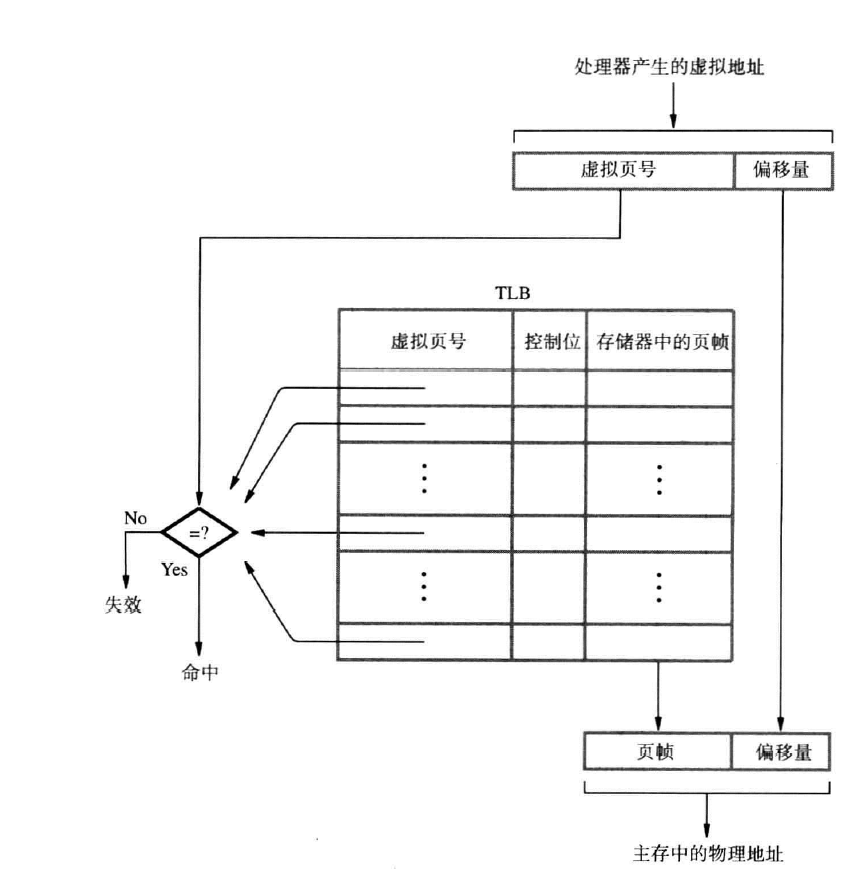
注:TLB需要空间存储页码,因为不按顺序存储,且需要一一比对。TLB Hit&Miss
当MMU在TLB中搜索页时,若找到,则提供物理地址,否则,在页表中搜索,同时更新TLB。页故障(page fault)
当TLB和页表中都没有找到要求的页,表明发生页故障,此时要求此页的程序被中断,控制权移交给操作系统,操作系统把请求的页从磁盘拷贝到主存中,此间CPU可能转而去处理其他的程序。传输完毕后,中断的程序恢复运行。
若仅在TLB中未找到,则称为miss弹出页
当主存满了之后,需要弹出主存中的页,即页的替换。
一般有三种: - LRU
- FIFO
- Software (OS) implementation
修改页
只考虑写回,直接写需要频繁的磁盘访问分析
优点
- 增加可地址空间
- 简化重定位:同一个程序可以在任意位置运行
- 减少启动程序的时间:并非所有代码和数据都需要全部放置到内存中
- 将程序员从覆盖(overlaying)的负担中解放出来
内部碎片(internal fragnebtation)(缺点)
当主存为每个页分配空间时,不能总是刚好分配完,主存最后一点不够一个页的空间也会塞入一个页,显然不是完整的页,称为内部碎片大容量的页的优点
- 页表大小减小,TLB能存储更多的页表项
- 传输速度加快
大容量的页的缺点
内部碎片(internal fragnebtation) 问题加剧
习题
1.Which one of the following about benefits of virtual memory is NOT true?
A. provide large address space B. relieve programmers from burden of overlays C. resolve internal fragmentation D. simplify relocation
C
2 . In a paging system, which of the following is NOT true?
A. When a TLB miss occurs, the operating system must copy the requested page from the disk into the main memory
B. Transferring larger pages to or from secondary storage is more efficient than transferring smaller pages
C. Paging has a problem called internal fragmentation
D. “Write though” is not suitable for this system
A
3 . A processor uses 46-bit virtual addresses with 2MB pages. Which bits in the virtual address correspond to the “offset” field?
A. The most significant 34 bits B. The least significant 12 bits C. The most significant 25 bits D. The least significant 21 bits
D
4 . A page fault is —-
A. an attempt by the computer to run instructions stored on the hard disk
B. the process the computer uses to start itself
C. an error the computer makes when a device driver is missing
D. an out of memory error
A
5 . About TLB, which of the following is true?
A. It’s a small cache which consists of a small portion of the page table
B. When a TLB miss occurs, the operating system must copy the requested page from the disk into the main memory
C. TLB misses can only be handled in hardware
D. Its content is accessed based on the address
A
6 . Suppose the paging hardware with TLB has a 90 percent hit ratio. Page numbers found in the TLB have a total access time of 100 ns. Those which are not found there have a total access time of 200 ns. What is the average access time?
A. 100ns B. 110ns C. 190ns D. 200ns
B
7 . True or False? A Translation Lookaside Buffer (TLB) acts as a cache for the page table.
T
8 . What are advantages and disadvantages of choosing smaller page size in a paging system?
Advantages: A small page size will result in less wasted storage when a contiguous region of virtual memory is not equal in size to a multiple of the page size.
Disadvantages: (1) The size of the page table is inversely proportional to the page size. Memory can therefore be wasted by making the pages smaller.
(2) Transferring smaller pages to or from secondary storage, possibly over a network, is less efficient than transferring larger pages.
9 . Under what circumstances do page faults occur? Describe the actions taken by the operating system when a page fault occurs.
A page fault occurs when an access to a page that has not been brought into main memory takes place.
The operating system verifies the memory access, aborting the program if it is invalid. If it is valid, a free frame is located and I/O is requested to read the needed page into the free frame. Upon completion of I/O, the process table and page table are updated and the instruction is restarted.
做题
- 给出page size,表示偏移量,即存储在其中的数据的位数。
- 给出映射方法
- 给出总的虚拟存储可寻址空间,根据偏移量求出虚拟页号
- 根据虚拟页号得到物理页号
- 根据物理页号和偏移量得到物理地址
- 现在对应到主存与缓存
注:所有的加减法都需要转换为二进制(从右到左)再计算
例如:物理地址12位,偏移量6位:00 1101,剩余转换为16进制是1E,则转换为2进制是01 1111 00 1101——0111 1100 1101——78D
辅助存储器
磁盘
磁盘有读写头,写入时将对应的磁体极化,当读取到变化的磁场时,就代表读取了数据1。
磁盘按同心圆分割为多个磁道(track),磁道按圆心角划分为扇区(secor),如下所示: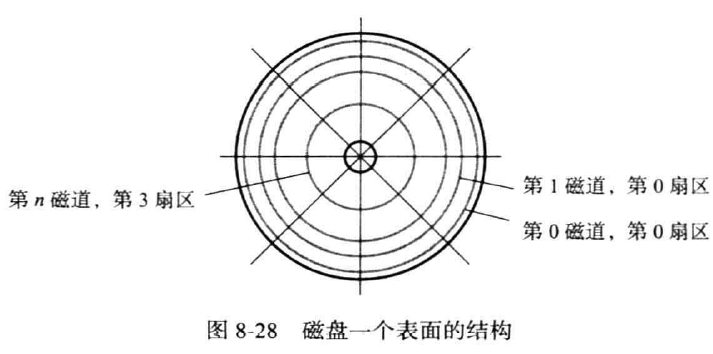
每个磁道的扇区数一致
磁盘分单面与双面,单面需要一个读写头,双面两个。
曼彻斯特编码
自同步时钟
温切斯特(winchestaer)技术
盘体和读写头放置在密闭的,去尘的空间内
优点:数据密度更大
读写
每个盘一个读写头,写头使用电流脉冲磁化材料,读头因为线圈运动发生电压改变
访问
数据被存储在磁道上,在每个扇区的开始,有一个扇区头(sector header),用来存储寻址信息,用来在选定的磁道上找到所需要的扇区(因为磁盘是先直接寻址,在顺序寻址,即要一个个比对);此外,还有纠错码(ECC),用来检测与纠正读写时发生的错误。扇区间还存在扇区间隙,用来区分不同的扇区。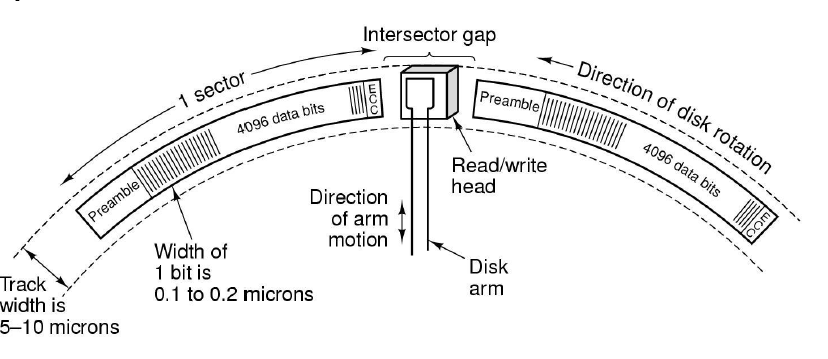
磁盘需要格式化,用来划分磁盘得到磁道与扇区,这通常也需要花费存储空间。
磁盘堆上所有的相同磁道和集合称为柱面(Cylinder),多个读写头按盘面搭在同一个柱面上。
磁盘一般以盘面为读取单位。
时间
- 寻道时间(seek time):把读写磁头移动到磁道所需的时间
- 旋转延迟(等待时间)(rotational time):读写磁头找到对应的扇区的时间。
- 访问时间(access time):前面两个时间之和;
习题
1 . The data of all tracks of a __ can be accessed without moving the readwrite head.
A. surface B. platter C. sector D. cylinder
D
2 . According to the specifications of a particular hard disk, a seek takes 3ms between adjacent tracks. If the disk has 100 cylinders, how long will it take for the head to move from the innermost cylinder to the outermost cylinder?
A. 3ms B. 30ms C. 300ms D. 3000ms
C
3 . A hard disk with 5 double-sided platters has 2048 tracks/platter, how many movable heads does it have?
A. 5 B. 10 C. 20485 D. 204810
B
4 . When we read a block of data from a disk into memory, the seek time refers to —-
A. the time required to move the read-write head to the proper track
B. the time required to position the read-write head and transfer the data block C. the time required to rotate the correct sector under the head
D. none of the above
A
5 . The amount of time required to read a block of data from a disk into memory is composed of seek time, rotational latency, and transfer time. Rotational latency refers to —-
A. the time it takes for the platter to make a full rotation
B. the time it takes for the read-write head to move into position over the appropriate track
C. the time it takes for the platter to rotate the correct sector under the head
D. none of the above
C
6 . A hard disk with 5 platters has 2048 tracks/platter, 1024 sectors/track (fixed number of sectors per track), and 512 byte sectors. What is its total capacity?
A. 5G B. 10G C. 15G D. 20G
A
指令集体系结构
指令和指令序列
计算机必须能够具备执行四种基本指令:存储器和寄存器数据传送,数据算数和逻辑运算,程序序列化和控制执行,输入、输出发送。
寄存器传送标记(RTN)
再此中,使用LOC表示存储单元地址,[ LOC ] 表示LOC的内容。R开头表示寄存器,箭头表示数据传输方向。
如:R2<-[LOC]表示把LOC中的数据传入R2。R4<-[R2]+[R3]表示把R2和R3中的数据取出,加法运算后写入R4。
以上为RTN表达式,式的右边为值,左边是单元名。
汇编语言符号(assembly language notation)
如:Load R2,LOC表示把LOC中的数据写入R2。Add R4,R2,R3表示把R2与R3值相加写入R4。
使用助记符表示执行的操作。比如Load使用LD缩减。不同的处理器的汇编语言使用不同的助记符。
RISC和CISC指令集
在现代计算机的指令集设计中,有两种根本不同的方法。如果每条指令恰好占据存储器的一个字,那么可以获得更高的性能。
每条指令必须恰好放入一个字限制了其复杂度,减少了不同的指令数目,表示为精简指令集(RISC)。
相对于RISC的是复杂指令集(CISC),他可以使用更复杂的指令,存储空间可以横跨多个存储器字。
RISC指令集介绍
特性
- 每条指令一个字长
- 使用Load/store体系结构
Store
有格式Store 源操作数,目的操作数,其运行方向与Load相反。
指令执行和线性序列(straight line sequence)
我们之前提及IR(指令寄存器) 与PC(程序计数器)。
PC包含将要执行的下一个指令的地址,当程序开始是,第一条指令必须放入PC,然后PC递增的读取以后的指令。这种执行的方法称为线性序列。
执行一条指令可以分为两个阶段:
- 取指令(fetch):PC根据其中的下一条指令的地址在存储单元中取出指令,随后放入IR中
- 指令执行(execute):IR对指令检查并确定要执行哪种操作,随后处理器执行此操作
在这两个过程中,PC自增。转移(branching)
也就是循环,如下图: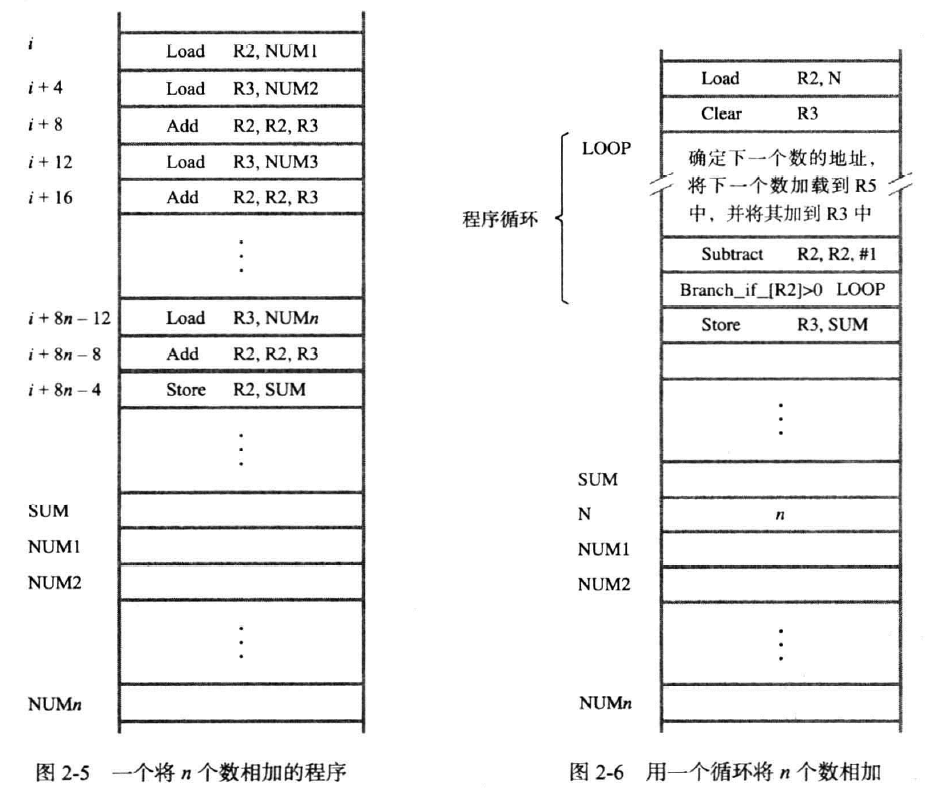
在左侧我们执行n次的加法,每次把值加入R2,最后存储到SUM中。
在右侧我们引入循环,使用R2记录循环的次数,LOOP内的内容为循环内容。Subtract R2,R2,#1
表示对R2的内容减一,其中#1表示值为1的常量。Branch_if_[R2]>0 LOOP
就是一个典型的转移指令,这类指令将一个新的指令加载到PC中,而不是使PC自增的访问下一个指令。被加载到PC中的指令称为转移目标(branch target),当循环条件满足时才进行转移,否则自增的执行下一个指令。
指令格式(instruction formats)(注)
机器指令(machine instruction) 是说明处理器电路必须执行的动作以完成预期的指令。
指令集(instruction set):处理器能执行的指令的集合
要素
- 包含操作码(Opcode),表示要执行的操作,用二进制码表示。
- 源操作数引用(Source operand reference),指定指令所需的操作数
- 结果操作数引用(result operand refence),指定操作的结果存放的位置。
源操作数和结果操作数可以存放在主存,虚存,寄存器,IO设备中 - 下一个指令引用(next instruction refence),表示在哪里找到下一个指令,即线性序列。
指令表示
在计算机中,指令以二进制的形式表示,指令被分为两部分:操作码和地址字段。
如下图:
指令设计准则
- 短指令优于长指令
- 指令格式中有足够的空间表示所有的操作
- 地址栏位数有限
地址字段格式(注-)
零地址指令
只有一个操作码的指令
一地址指令
通常,可以隐含地理解第二个操作数是在处理器的累加器中
二地址指令

A1为结果操作数,A2为源操作数
三地址指令

A2,A3为源操作数,A1为结果操作数
指令长度(instruction length)
根据地址指令的数量,能够为每个操作码和地址指令的长度可能也不同。
指令长度一般固定,根据不同的规则区分不同的指令格式。
做题
给出指令长度与操作码长度,给出地址长度的数目:
此类型题从三地址指令向零指令地址过度,我们分配的是操作码,在此之外留意剩余空间是否能容纳指令地址:
三地址指令
地址为4位,三个地址位共12位,剩下左边4位表示opcode,得到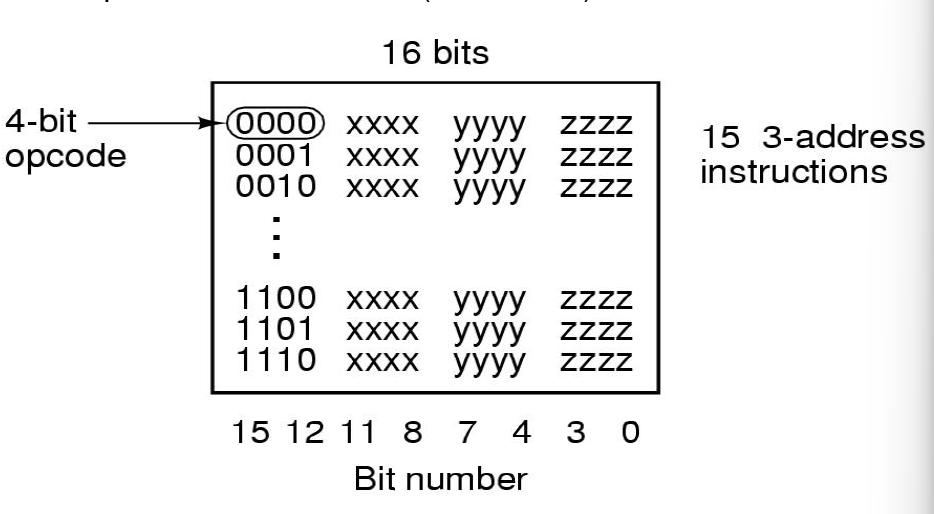
第二个16进制字符的二进制由0000到1101,表示15个三地址指令
二地址指令
我们需要一个特征区分三地址和二地址,在上一个步骤中,前4位不可改变,后8位无意义,需要留给其他指令格式,所以要取左侧第5~8位的某个序列固定地表示现在是二地址,故使用1111表示二地址,即前4位都是1
现在剩下右侧8位,我们逐个分配给14个二地址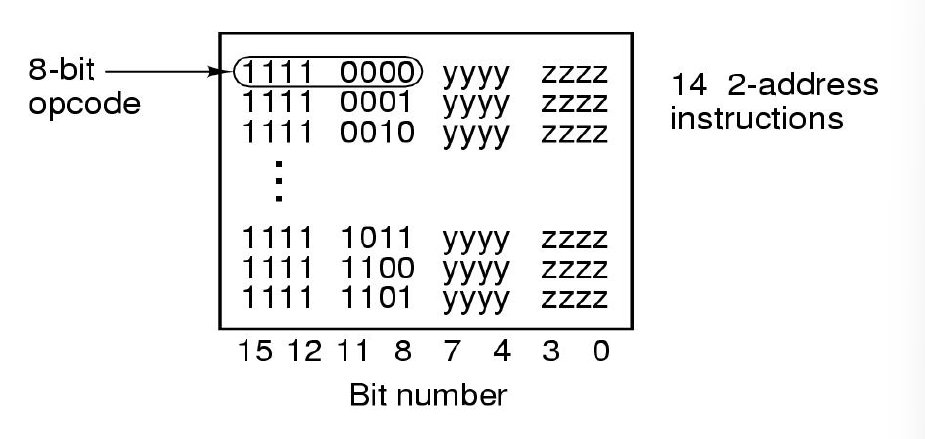
一地址
和上文一致,我们使用1110和1111表示一地址,即前6位都是1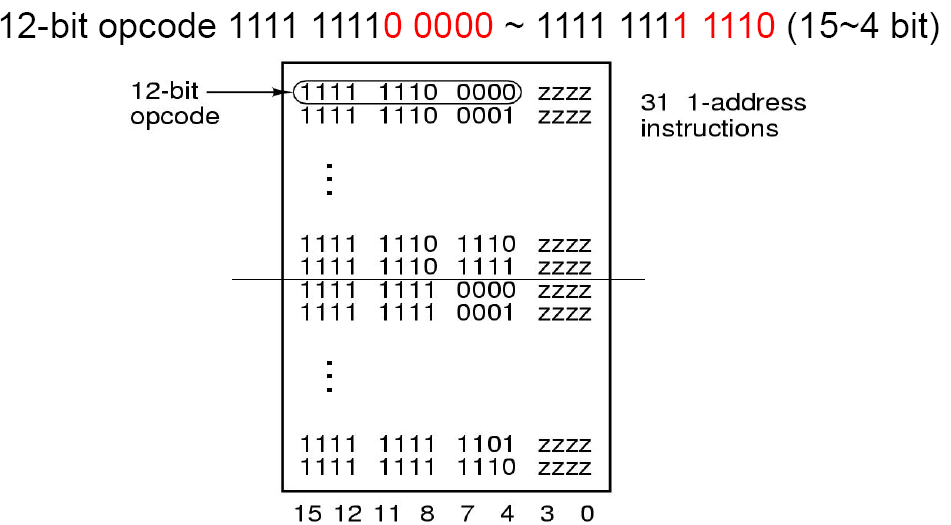
零地址
零地址不需要地址字段,全部分配即可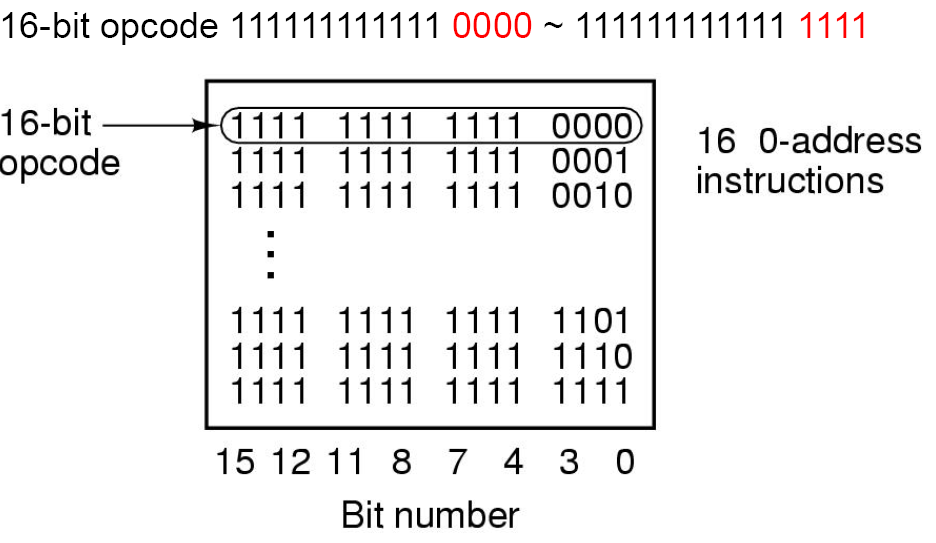 完成。
完成。
寻址方式(addressing modes)(注-)
如下图,RISC风格的寻址方式有6种: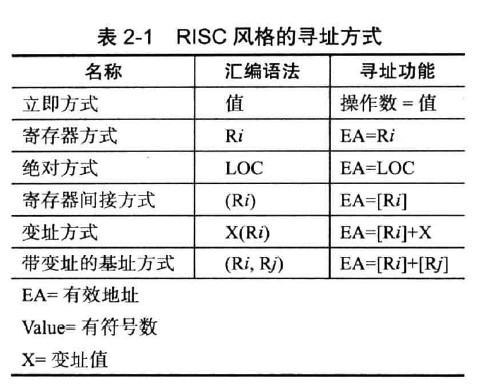
现在逐个介绍
寄存器方式
在此前的例子中,我们使用$R_i$表示不同编号的寄存器,操作系统根据名称找到对应的寄存器
优点
一次地址计算,空间占用小
缺点
寻址空间小
变量与常量寻址方式
绝对方式(absolute mode)
假如我们用变量名声明了一些变量,那么我们可以通过这些变量名访问地址空间,如$NUM1$,可以表示此空间的地址而非单独的名称。
这些变量存储在主存中,即访问主存中的数据使用绝对方式。
优势
只有一次的内存访问
缺点
指令永远指向一个固定的地址,寻址空间有限
立即方式(immediate mode)
我们用#200,表示一个常量值(同时也是一个地址),使用时不再需要寻址而是直接拿取值。
优势
不需要访问地址即可获取数据
缺点
数的大小取决于地址的位数
间接寻址方式(indirect mode)和指针
主存间接寻址
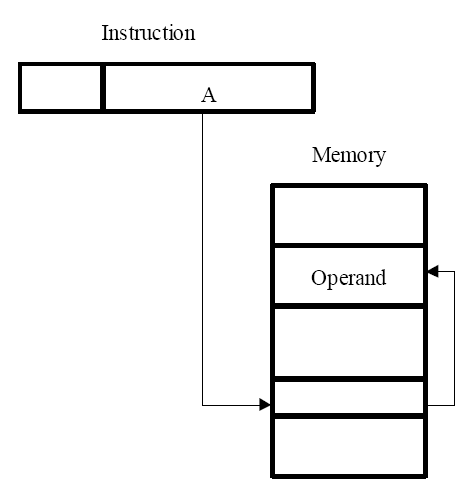
在我们之前给出的关于循环的例子中,我们简单的用文字描述了循环内部信息:在每个循环开始时,确定下一个数的地址,加载到$R_5$中,再加到$R_3$中。我们使用处理器寄存器来保存所有待加数的地址,每次遍历时,我们递增寄存器,把地址加载到$R_5$中,我们把$R_5$称为指针,因为它指向了下一个待加数的存储空间。
间接方式和指针的使用在程序设计中是一个重要且强大的概念,可以使用相同的代码对不同的数据进行操作,一般在CISC中使用。
我们使用(R5)来表示间接寻址,如Load R2,(R5)。
优点
寻址空间大,若绝对寻址的大小为n,则间接寻址的大小为2n
缺点
需要计算两次地址
寄存器间接寻址(register indirect mode)
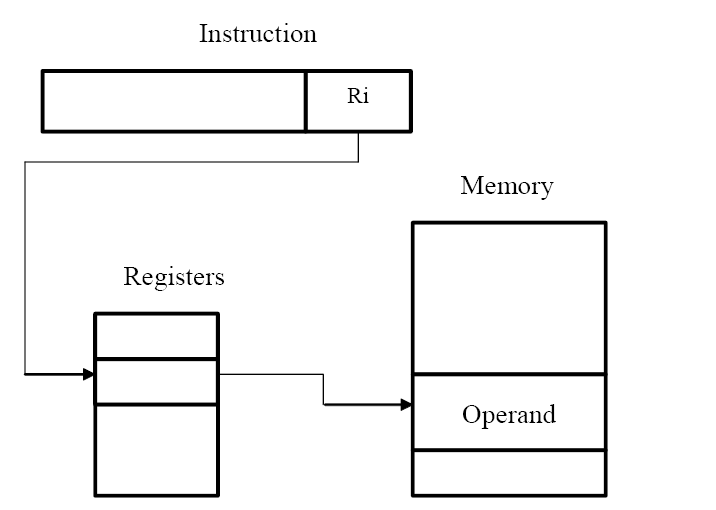
优点
以较小的寻址空间表达了更大的寻址空间,减少访问时间
现在我们更新循环内容,如下图所示: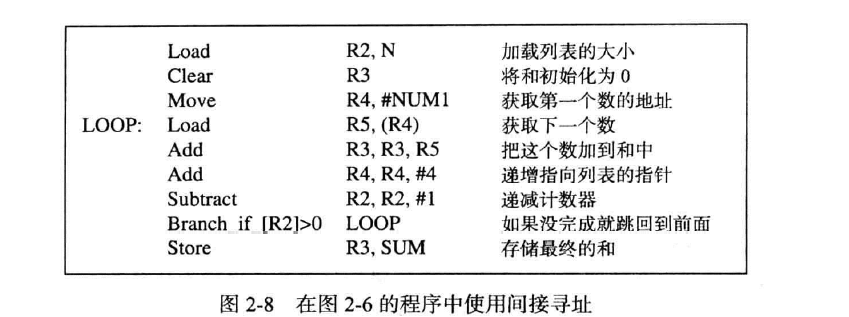
其中,我们使用#NUM1表示NUM1的地址,那么R4成为一个指向NUM1存储空间的指针。
我们再给出一个例子:在c++中,使用
int c=10;
int *b=&c
int a=*b;
则此代码的后一条可以被编译为:
Load R2,b
Load R3,(R2)
Store R3,a
多级间接寻址(multilevel indirect addressing):
- 多级间接寻址:EA(有效地址)可以通过多层间接寻址得到。
- EA = […[A]…]:表示有效地址(EA)可以通过嵌套层级的方式,从一个初始地址A经过多个间接地址获取到最终的有效地址。
- 地址中的间接标志位 (I bit):在一个完整的字(word)地址中,有一位被用作间接标志位I。
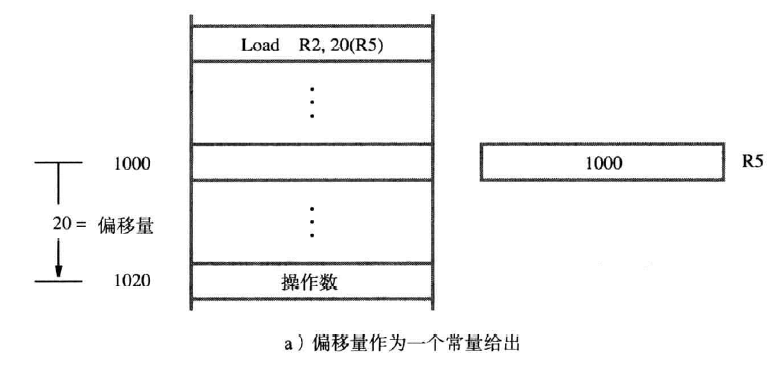
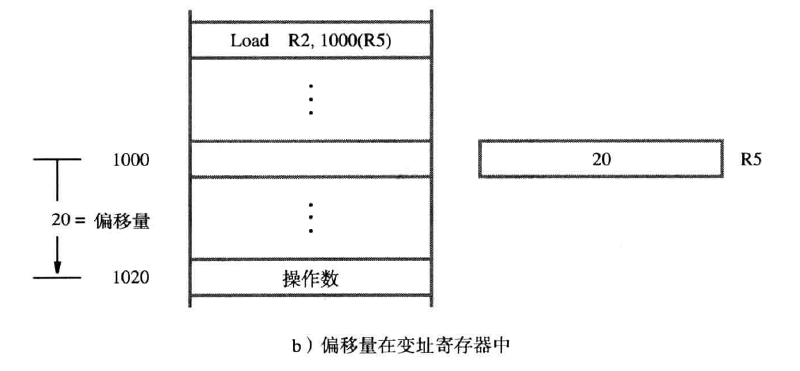
基址寻址方式(base index)
基址寄存器(base register)
将偏移值存入基址寄存器,地址存储在变址寄存器中,如(Ri,Rj)。
基址变址
在Ri,Rj前加上常数偏移值,如X(Ri,Rj)。
堆栈(stacks)
- 后进先出(LIFO),弹出的一端称为栈顶,另一端称为栈底。有时也将堆栈称为下推栈。
- 堆栈一般使用主存的一部分组成
- 有一个特殊的处理器堆栈(在存储器中)
堆栈可以用来存储中断嵌套,子程序嵌套,递归,临时变量处理器堆栈
CPU中存在一个栈指针(SP) 寄存器来指向处理器堆栈的栈顶
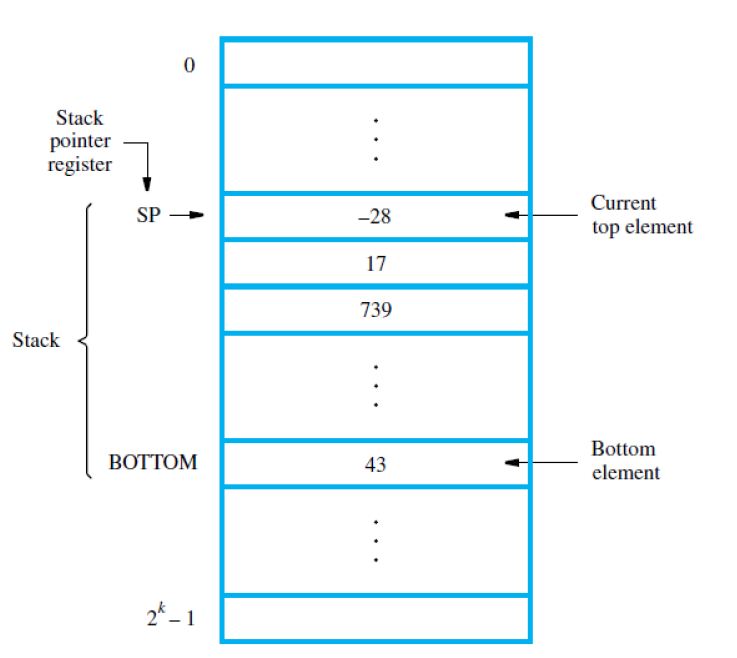
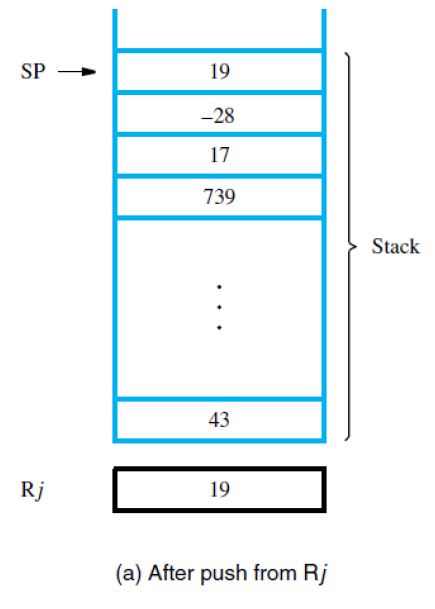
故使用push时为Subtract SP, SP, #4 Store Rj,(SP)
使用pop为Load Rj,(SP) Add SP,SP,#4。+4时栈指针指向下一格。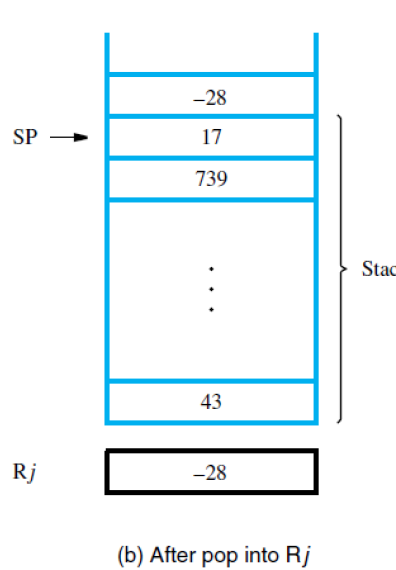
子程序(Subroutines)
子程序是一个封装好的程序块,考虑到我们常常有对不同的数据应用同一组指令的行为,所以实现子程序以应对这些情况。
是一种特殊的转移。
主程序在需要使用到子程序时,为了节省空间,我们在存储器中存放一份子程序的拷贝,下次使用时跳转到子程序的起始位置即可,此操作称为调用(Call)。
执行完子程序后,需要跳回原主程序的位置,此方法称为跳回(return),为了能够回到原位置,使用Call时必须保存PC中的内容。
子程序链接法(subroutine linkage)
上述的能够在计算机中调用子程序并从子程序返回的方法称为子程序链接法
Call方法存储的PC的内容一般存储在链接寄存器(link register)。
Call
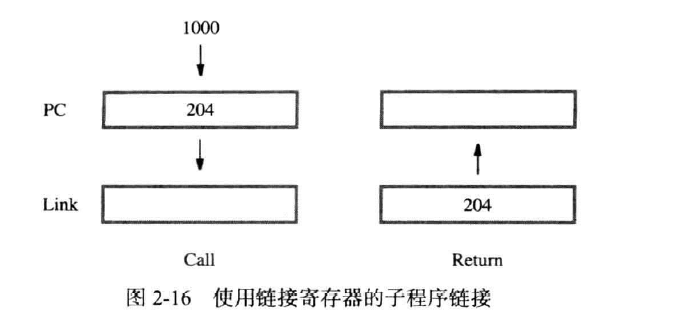
CISC指令集
CISC指令集不受限于load/store体系结构(load/store archecture)(此体系结构中只能对处理器寄存器中的操作数执行算数和逻辑运算),CISC的指令不需要放在一个单字中,一个指令可能在一个字中,也可能跨越多个字。
Move指令
相别于Load和Store,Move的格式为Move destination,source,两个操作数可以在主存中或寄存器中,但至少有一个在寄存器中。
其他寻址模式
自动增量和自动减量方式
自动增量(autoincrement)
操作数使用(Ri)+,表示访问寄存器Ri中的有效地址后自增寄存器的内容,自增的大小为被访问的操作数大小相符的值。
自动减量(autodecrement)
先自减寄存器,再访问其中的操作数的有效地址,使用-(Ri)
加减的顺序与入栈出栈的顺序有关,入栈是自减后移动数据,出栈是访问栈顶再自加
相对方式(relative mode)
使用PC代替通用寄存器(Ri)进行变址寻址,用X(PC)来表示距离PC所指向的地址距离X的指令。
可能更为灵活
条件码(condition codes)
上文提及,CISC可以执行不限于算术与逻辑的运算,处理器执行的运算通常会产生如正数,负数或0等结果,处理器保存这些信息以便后续的条件转移指令执行。
处理器保存的这些位是条件码标志(flags),他们存储在条件码寄存器或状态寄存器(status register)中,以下为4个常用的标志:
- N(负数):若结果是负数则置为1,反之置为0
- Z(零):若结果是0则置为1,反之为0
- V(溢出):若结果溢出,则置为1,反之为0
- C(进位):若结果有一个进位输出则置为1,否则为0

在算术操作Subtract后,条件码重置,若n次循环没有结束,那么N与Z就都为0,则N+Z=0,不满足Branch的要求,回到循环起点。
对信号位V,有指令Branch_if_overflow判断是否溢出
对信号位C,有指令Branch_if_carry判断有进位习题
1 . In which addressing mode the operand is actually present in instruction?
A. Immediate mode(立即数模式);B. Direct mode(直接模式);C. Register mode(寄存器模式);D. Index mode(索引模式)
A
2 . In the following addressing modes, which does not belong to RISC style computers?(在以下寻址模式中,哪个不属于 RISC 风格计算机?)
A. absolute mode(绝对模式);B. register indirect mode(寄存器间接模式);C. index mode(索引模式);D. indirect mode(间接模式)
C
3 . The condition flag Z is set to 1 to indicate(条件标志 Z 被设置为 1 表示)
A. the operation has resulted in an error(操作导致错误);B. the operation requires an interrupt call(操作需要中断调用);C. the result is zero(结果为零);D. there is no empty register available(没有可用的空寄存器)
CRISC与CISC对比(注-)
RISC
- 寻址模式简单
- 所有指令在一个字内
- 总指令数少
- 寄存器上实现算术与逻辑运算
- 使用Load/Store架构传输
- 每个程序执行更多的指令
简单的指令使得设计更快的硬件变得简单CISC
- 更复杂的寻址方式
- 指令不局限于一个字
- 指令集有更多的指令
- 主存上实现算术与逻辑运算
- Move架构传输
- 一个程序使用更少的数据
更复杂的指令使得设计快速的硬件变得困难习题
1 . Which of the following is not the characteristic of RISC style?
A Simple addressing mode
B All instructions fitting in a single word
C Fewer instructions in the instruction set
D Arithmetic and logic operations that can be performed on memory operands as well as operands in processor registers
D
2 . Compare the RISC-style and CISC-style instruction set. Please list 3 differences at least.
基本处理部件(basic processing unit)
一些基本概念
- 程序计数器(PC),读取下一条指令的地址,一次一条
- 指令寄存器(IR),指令在IR中译码,保存该指令直到此指令被执行完成或中断。
一般步骤
- IR取出PC的指令,如
IR <-- [[PC]] - 递增PC,如
PC <-- [PC]+4 - 执行指令
前两部为取指令阶段,后一步为指令执行阶段一般动作
指令要求的动作一般包括: - 读取一个给定的存储单元的内容,并装入处理器寄存器中
- 读取多个寄存器的内容
- 执行算术或逻辑运算,并将结果放入处理器寄存器
- 将处理器寄存器中的数据存入指定的存储单元中
数据处理硬件(data processing)
大阶段
如下图,将一次计算分布在一次长时间的时钟上升沿中
小阶段
考虑到流水线(pipeline),我们将一次计算分为多个小阶段,每个时钟周期缩短,但总计算时间不变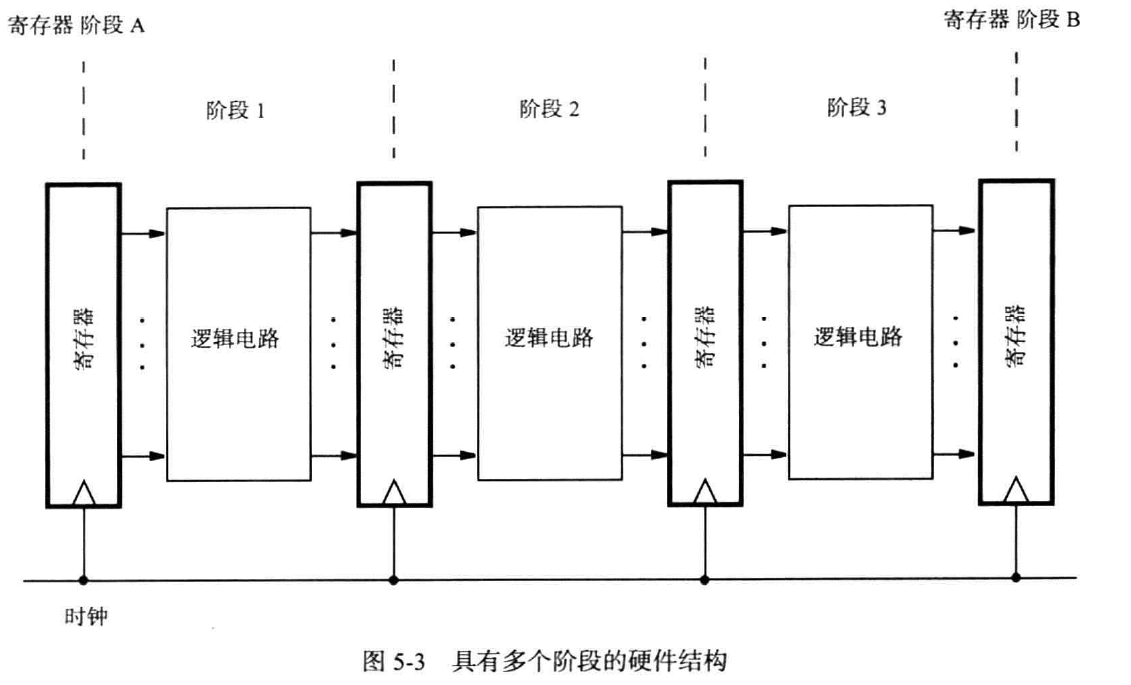
指令的执行
再RISC中,处理器一般有5个硬件阶段,每条指令我们也分5步进行
Load
考虑 Load R5,X(R7),有如下步骤
- 从存储器中取出指令,PC自增
- 译码并读取R7
- 将X与R7相加
- 将上一步的值作为地址读取相应单元中的内容
- 将内容装入R5
Add
对Add R3,R4,R5,有如下步骤
- 取出指令并自增
- 译码读取R4,R5的值
- 计算二者的和
- 空指令(即Add操作只需5步完成,但考虑到流水线的效率,增加为5步)
- 将结果装入R3
Store
对Store R6,X(R8),有步骤
- 取出指令,自增
- 译码读取R6,R8
- 计算地址
- 将内容装入X(R8)中
- 空操作
统一
- 取出指令,自增
- 译码并读取寄存器中的内容
- ALU
- 若包含存储器操作数,则读或写
- 如需要,将结果写入
因为X可以为0,实际中我们只需要实现变址操作,对其他操作,令X=0即可
硬件组件(hardware components)
寄存器文件(register file)
我们把多个寄存器集合在一起,再搭配上接入电路使得能同时访问两个不同的寄存器,并使其内容出现在两个独立的输出端A和B中,形成了一个寄存器文件。
寄存器文件中还有一个数据输入端和地址输入端,前者用于写入数据,后者用于选择写入的寄存器
实现
双端口寄存器文件(2-port register file)
使用一组寄存器,接入双重的数据通路和接入电路
如下图: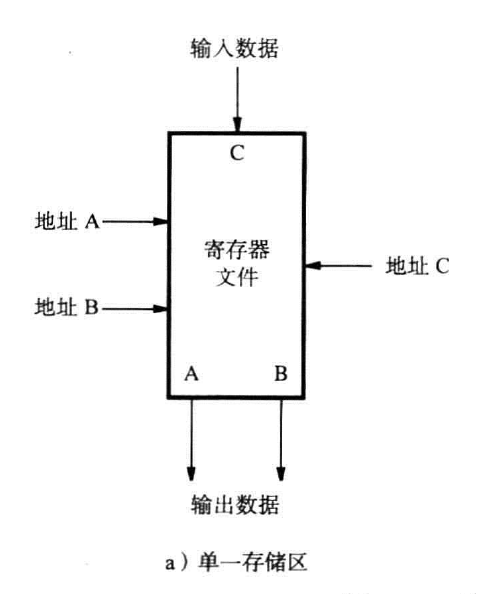
双存储器实现(two single-ported memeory blocks)
用两个存储区存储寄存器的副本,读写单独作用在每一个副本上
如下图: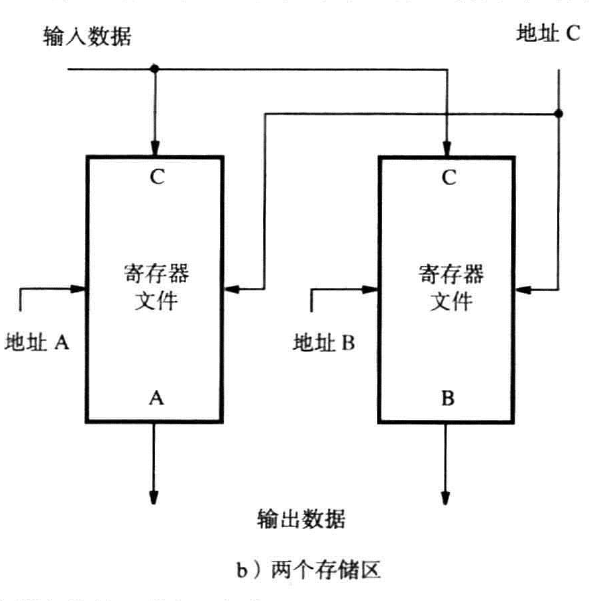
ALU
对于以上的每个指令,都需要ALU的参与,或是计算内容和,或是计算地址和
如下图: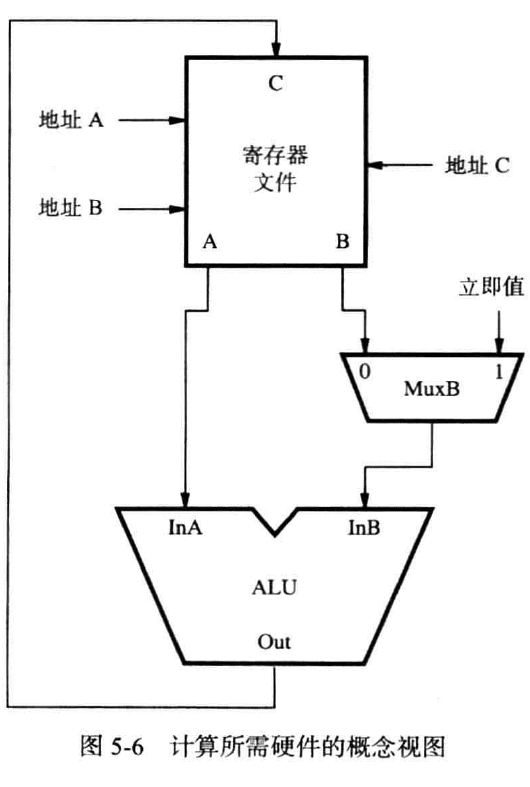
数据通路(datapath)
指令处理包括指令读取和指令执行两个阶段,我们也将处理器划分为两个部分,分别处理两个不同的阶段。如下图: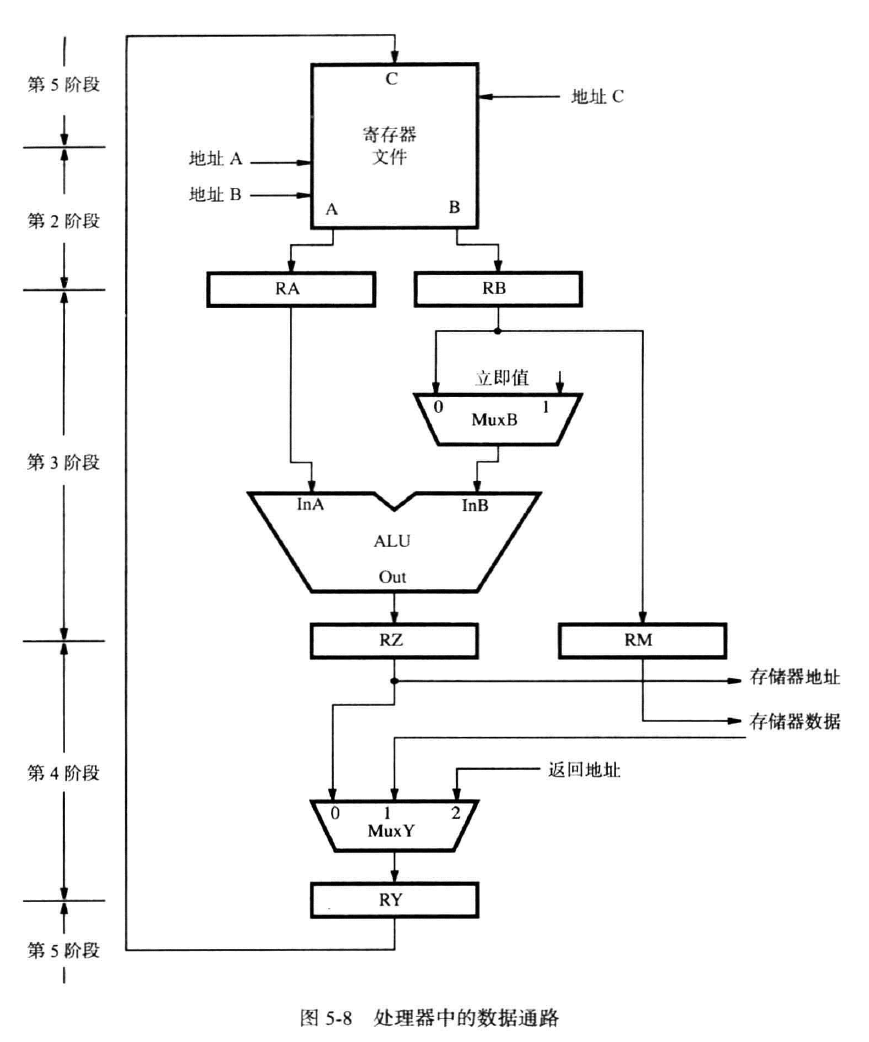
指令执行
指令执行包括:源寄存器,ALU,存储器访问,目的寄存器四个步骤
Load
把数据加载到寄存器中,第二阶段读取后一个地址,第三阶段与偏移值取和后作为存储器地址,第四阶段得到存储器数据,第五阶段存入对应的寄存器
Add
第二阶段读取后两个寄存器的内容,第三阶段求和,第四阶段直接输出,第五阶段写入
Store
第二阶段读取两个寄存器的地址,第三阶段计算和,第四阶段输出和代表的存储器地址和前一个寄存器中的数据,无第五阶段
指令读取
指令读取包括取指令(instruction fetch)
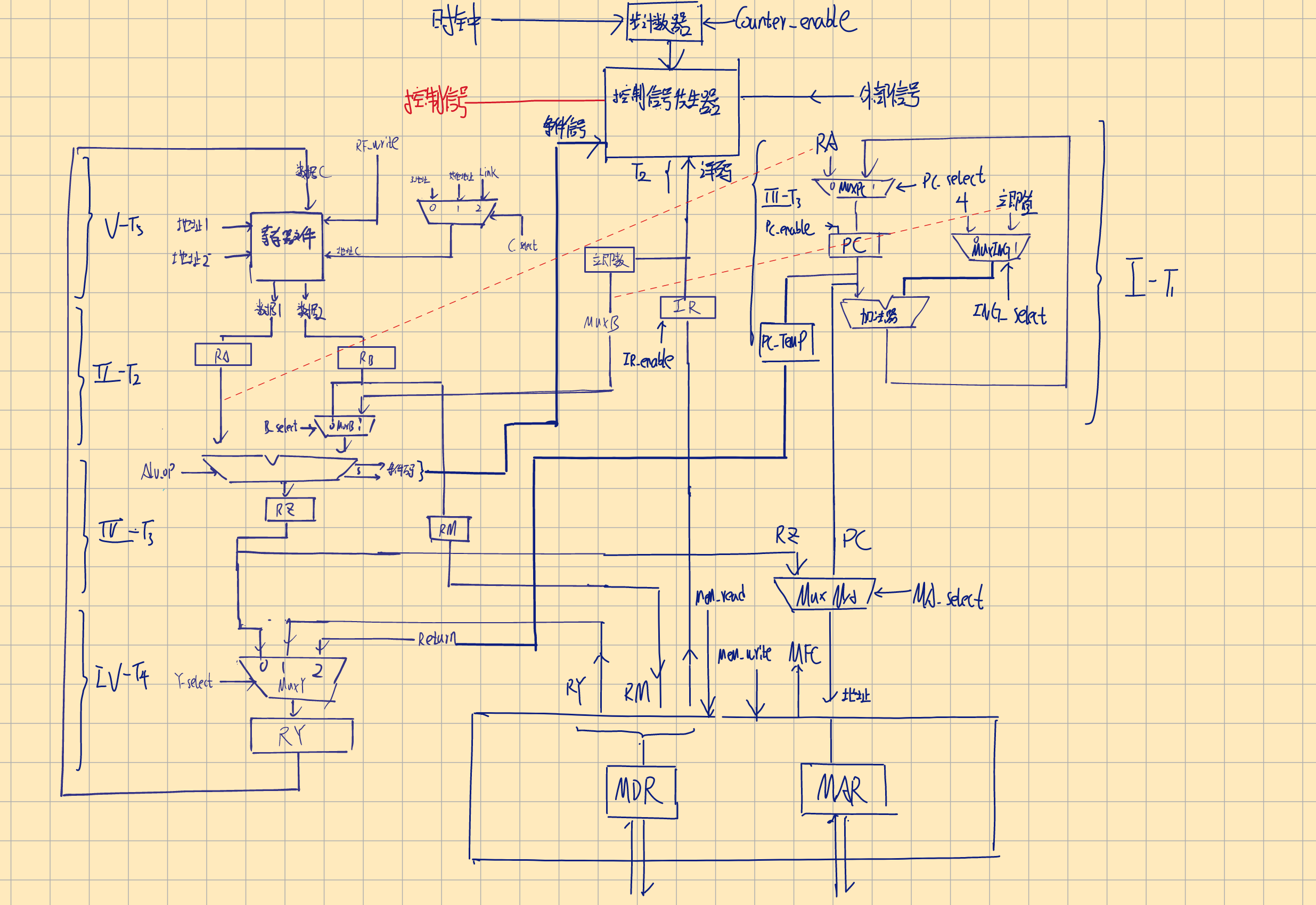
PC自增
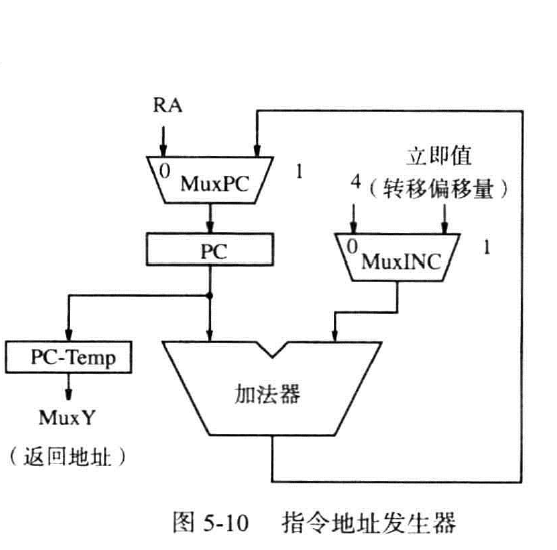
如图,MuxINC选择正常的自增常数4或IR给出的偏移量,后者常用于中断或子程序的定位(即相对方式)。与PC原有的值相加后得到新的地址。MuxPC选择其加法器的结果或此前用链接存储器存储的返回的地址。当因为第一次进入中断或子程序而需要记录原地址时,就把原地址存储在寄存器PC-Temp中,再作为返回地址存储到链接寄存器中。
IR存储指令
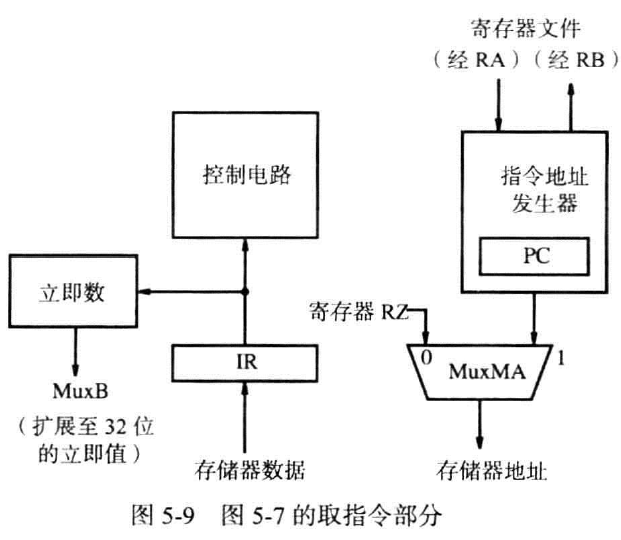
PC一般都被封装在一个指令地址发生器(instruction address generator) 中,因为小程序或中断,所以需要和外界的寄存器交换信息。
在存储器——处理器接口中,传入的存储器地址来源有二:PC传来的指向下一个指令的地址;某些指令要求的存储器地址
在取指令阶段,PC传入指令地址,对应的存储器数据传入IR,控制电路会检查IR中的指令,生成对应的控制信号等。IR会保存此指令直到完成该指令的所有阶段,此外,指令中涉及的立即数扩展到32位后被发向MuxB和PC
指令的读取和执行操作(注-大题)
Add
对指令Add R3,R4,R5,我们有如下操作步骤

第一步:PC中的指令地址被取出,读取到存储器数据后装入IR,PC自增
第二步:对指令译码,如下图:
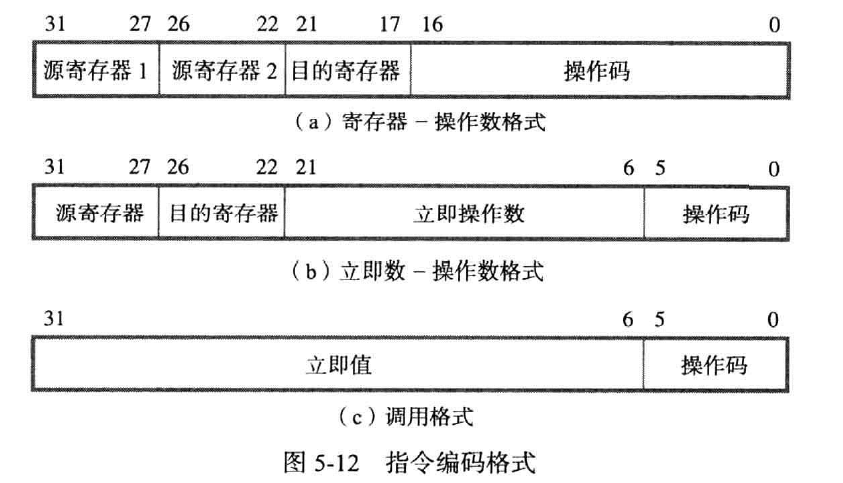
对本指令,前两个地址位是源寄存器,将R4中的内容提取到RA,将R5中的内容提取到RB
第三步:计算两个寄存器中的内容之和,存入RZ
第四步:将RZ中的值存入RY
第五步:将RZ中的值存入R3
考试中此题一般按操作步骤中的符号所示作答
剩下两个步骤:
Load&Store(注:第一步还应加上等待MFC)

注:Store指令中,第四步的读取存储器应该为存储器数据
做题时注意要求和的值写入RZ,作为数据的值写入RM
无条件分支
- 与上文一致,老三套
- 译码
PC<-[ PC ]+Branch offset- 无
- 无
条件分支
以Branch_if_[R5]=[R6] LOOP为例 - 老三样
- 译码,
RA<-[R5],RB<-[R6] - 对比寄存器中的值,如果满足条件,则
PC<-[ PC ]+Branch offset - 无
- 无
Call(注意)
以Call_register R9为例 - 老三样
- 译码,
RA<-[R9] PC-Temp<-[PC],PC<-[RA]RY<-[PC-Temp]链接寄存器<-[RY]
注意:第三步要要对PC和PC_temp修改,第四步获得内容,第五步再写入等候时间(wait for memory)
处理器-存储器接口提供了一个MFC(memory function completed) 信号,来表示向内存所求的数据是否已经找到。
若数据已在缓存,则此信号提前于向主存发送数据请求的信号产生;反之,当数据从主存中找到,转移到缓存中后,此信号才产生控制信号(control signals)
我们在这一节中丰富上一节的三个控件的信号元素。
首先我们对器件分类,分为需要信号控制和不需要信号控制的分类
对于RA,RB,RZ,RY,RM,PC-Temp,这些寄存器需要一直启用,以存储每一步中传入的数据,即其必须不断地接受数据而不加选择,他们只受时钟信号控制
对于复用器和IR,PC等器件,部分功能的使用需要信号指示
先给出图: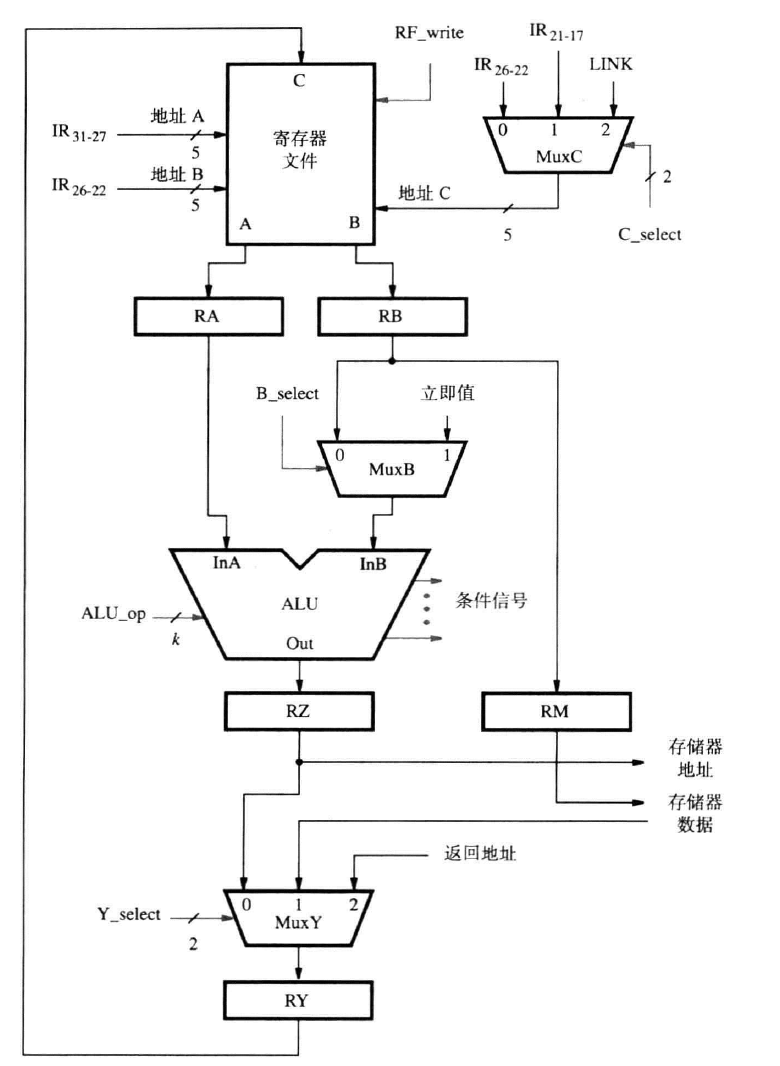
从上往下看:
我们在指令的第五步中常常遇见需要把数据传入寄存器文件的操作,现在扩展寄存器地址输入接口。
- MuxC复用器有4个输入,接受三指令的第21-17位,其他指令的26-22位和Call指令指定的链接寄存器,还接受一个选择信号C_select(2位,表示范围为0-3)
- 当RF_wirte发出后,新数据才会装入所选择的寄存器中
在对立即值的选择中:
- MuxB只有一个输入B_select,一位,选择RB或立即值
在ALU的运算选择中
- 假设输入ALU_op有k位,则其可以选择$2^k$种运算
- 条件信号(condition signals),此前提及ALU会指示比较运算的结果
在处理器-存储器接口处的选择中: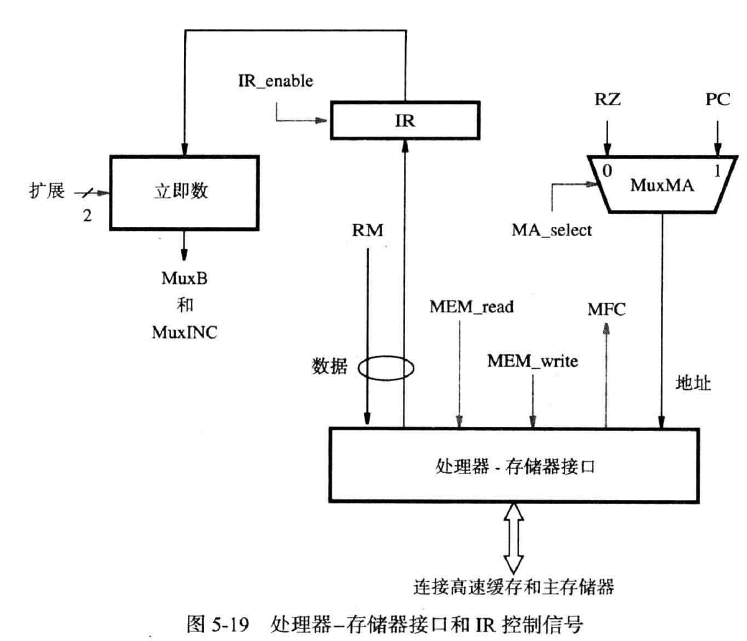
- 我们在此前提及,此接口只有两个地址输入:PC,RZ。这里使用MA_select选择两个中的一个。
- 使用MEM_read,MEM_write区分读写操作,当对应的信号传来时,才进行相应的读写操作。
- 对读指令,当MFC响应时,IR_enable才被激活,IR才读取指令;对读写操作,只有MFC响应时,才表示操作完成
- 对指令中时立即数,有三个扩展:16位无符号,16位有符号,26位特殊处理,需要两位的选择信号
- 有时RM会传来存储器数据,但有时也需要发出存储器数据到RY
在指令发生器中: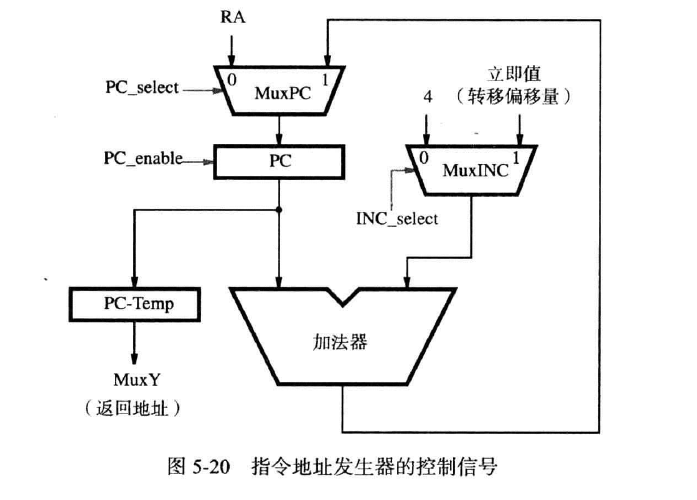
- 使用ING_select选择两种立即值
- 使用PC_select选择寄存器中的Return或自增
- 使用PC_enable,当其被激活时,MuxPC才传入数据到PC
硬件控制(Hardwried control)(不考表达式)(注-)
此节研究处理器如何产生所需要的控制信号,有两种方法:硬件控制(hardwires control)和微程序控制(microprogramming)。
我们需要解析指令来了解需要哪些指令,还需要根据当前的步数来激活对应的指令,还需要根据ALU比较运算的结果决定数据的流向,还需要根据外界信号,比如中断来控制指令执行。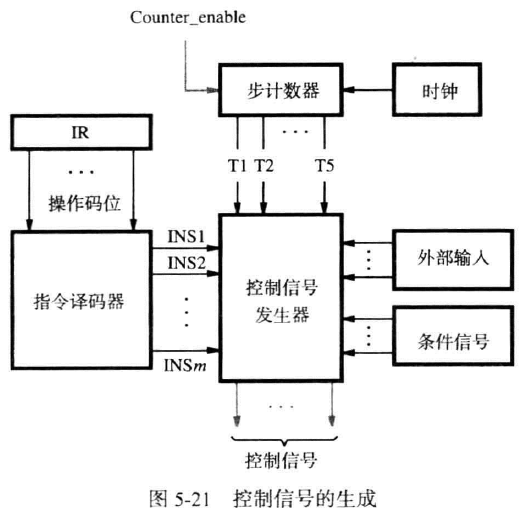
指令译码器(instruction decoder) 解读指令的opcode和寻址模式信息,根据opcode的不同,设置不同的运算信号,根据寻址模式的不同使用不同的信号模式获得数据
步计数器(step counter) 在每个对应的时钟周期内将对应周期的信号($T_1$到$T_5$)激活,表示现在正在哪个周期
控制信号发生器(control signal generator),作为组合电路,立刻产出指令运行的必要信号
控制信号的设置取决于:
- 步计数器
- IR
- 计算结果或比较结果
- 外部输入信号
数据通路控制信号
我们尝试使用指令名,步骤名等拼凑出对应信号的表达式
如写入寄存器的操作均发生在第五步,那么RF_write=T5(ALU+Load+Call)
但对于不需要步数对应的,例如立即数选择B_select=Immediate,其中Immediate表示所有在IR中使用立即数的指令。存储器延迟处理
步计数器一般来说会自增的使信号按$T1$到$T5$的顺序发出,但是,若在某个步骤访问存储器发生miss的时候,这种自增的发送信号的方式就行不通了。我们需要在某个步骤禁用步计数器以等待实际步骤完成,我们使用控制信号WMFC来表示是否有写存储器操作,使用Counter_enable信号指示步计数器运作。若WMFC没有被激活,则后者enable信号被激活
对PC而言,只有当上一个操作结束,且PC_enable被激活的条件下,其才会自增。
CICS风格的处理器(了解,待补充)
CICS风格的处理器将部件分离,各个部件使用总线连接,总线是连接多个设备的一组线路组成的能够使数据在两个设备之间传输。
为保证同一时刻只有一个设备驱动总线,设置一个三态门。
微程序控制(microprogramming)(注)
使用软件而非硬件的方法生成控制信号的方法,这个软件存储在一个特殊的存储器中,作为微程序。它一般存储在处理器中的微程序存储器(micropogram memory)或下文的控制存储器中 中。
对每个信号,我们使用一个字中的一位来表示其状态。字长为信号数,称为控制字(control word) 或微指令(microinstruction)。对每一步操作,都会生成一个控制字存储在微程序存储器中,微程序存储器中还存在下地址,存储下一条微指令。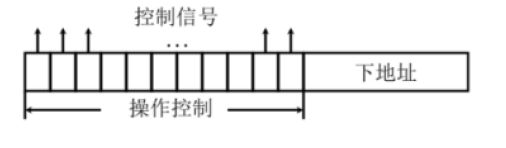
长微指令(long microinstruction)
缺点:
每个信号独占一位,利用率少
分组微指令(Grouping microinstruction)
将不能同时出现的信号放在一组,再通过二进制解码的形式缩减位数
优点:减少了每条微指令的大小
缺点:需要更多的解码电路
对一条指令的五步操作构成的微指令序列称为微程序(microprogram)或微例程(microroutine),微程序存储在控制存储器(contrl store) 中。微程序控制部件存在一个微程序地址发生器(microinstruction address generater),生成了IR存储的指令对应的微历程的起始地址以及借助$\micro PC$连续的访问下一个微指令,$\micro PC$(微程序计数器用于自增微指令地址发生器给出的初始起始地址,来产生下一条微指令的地址,下地址某位指示了微例程的结束,若此位为1,则地址发生器将地址返回到第一条微指令处。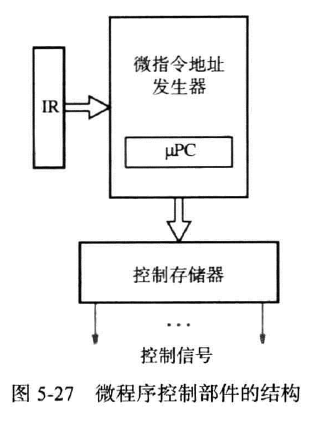
优缺点分析:
对硬件控制:
1. 操作速度快
- 成本高
- 不灵活
- 需要极高的时间成本设计新增的功能
对微程序 - 成本低
- 灵活性高
- 速度慢,延迟高
习题
1 . In hardwired control unit, the required control signals are
determined by the following information except .
A. contents of the control step counter
B. contents of the condition code flags
C. contents of the instruction register
D. contents of the program counter
D,B是条件码
2 . In microprogram-controlled machines, the control signals
required by a machine instruction are generated by a .
A. control store
B. control word
C. microroutine
D. microinstruciton
D,注意此题,有些问题
3 . The microprograms for all instructions in the instruction set of
a computer are stored in a special memory called the .
A. memory controller
B. main memory
C. cache
D. control store
D
4 . In microprogram-controlled machines, the relationship between
the machine instruction and the microinstruction is .
A. a machine instruction is executed by a microinstruction
B. a microinstruciton is composed of several machine
instructions
C. a machine instruction is executed by a microprogram,
which is composed of several microinstructions
D. None of the above
D
5 . What are the advantage(s) and disadvantage(s) of hardwired
and microprogramed control?
The main advantage of hardwired control is fast operation.
The disadvantages include: higher cost, inflexibility
when changes or additions are to be made, and longer
time required to design and implement such units.
Microprogrammed control is characterized by low cost and
high flexibility. Lower speed of operation becomes a
problem in high-performance computers.
流水线(pipelining)
基础概念
安排硬件架构使得多个操作可以并行的执行的方法,称为流水线。基本思想为:前一个指令未完全执行时就有一个新指令开始执行。
是多条(multiple)指令的重叠(overlap)执行
管道深度(pipeline depth):一个流水线的阶段数量
延迟(latency):在管道中执行一条指令总共需要多久
吞吐量(througout):每秒完成的指令数量
管道段(pipe segment):流水线的某个阶段
我们将一条指令分为五步:取指令,译码,计算,访存。按并行方式执行,如下图所示: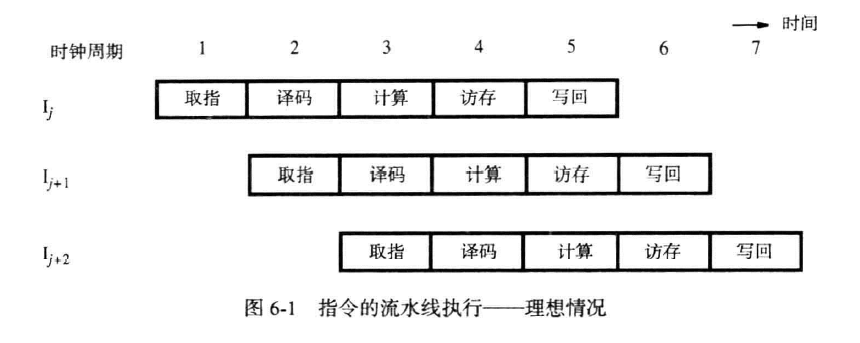
流水线结构(了解)
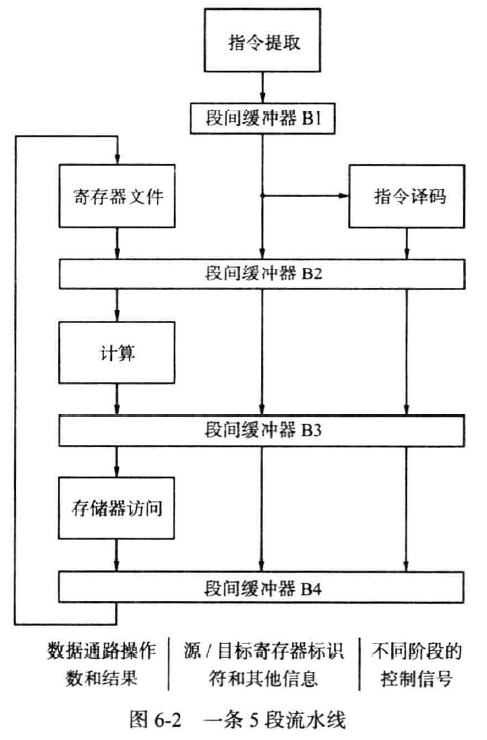
段间缓冲器(interstage buffers)
- 段间缓冲器B1向译码阶段提供一条新提取的指令
- 指令译码得到控制信号的设置值,寄存器地址,从寄存器文件中取得内容放入段间缓冲器B2
- 段间缓冲器B2向计算阶段提供寄存器文件中读取的两个操作数,寄存器标识符,立即值,用作子程序调用返回地址的递增后的PC值(PC自增,指向了下一条指令,即Call执行后必须存储的当前的指令地址)
- 段间缓冲器B3保存ALU的计算结果,在译码阶段读取的寄存器文件的部分数据,PC自增后的值(以便应对Call后存储值)
- 段间缓冲器B4向写回阶段提供一个即将写入寄存器文件的值,这个值可能为:ALU的结果,存储器访问的结果
流水线并没有加速一条指令的执行,但他减少了指令的平均时间
习题
1.What is the first stage in a typical five-stage CPU pipeline?
A. Fetch B. Decode C. Compute D. Write
A
2.When multiple-instructions are overlapped during execution of program, then function performed is called
A. Multitasking B. Multiprogramming
D
C. Hardwired control D. Pipelining
3.Ture or False? Pipelining increases processor performance by decreasing the execution time of an instruction.
F
流水线问题(pipeline issues)
冲突(hazard):引起流水线停止的情况
数据冲突(data hazard):一条指令要求修改后续指令读取的寄存器,写入寄存器文件的操作往往在第五步,而此时后续的指令或许已经执行到了访问寄存器文件的步骤,为了得到正确的结果,后面的那条指令必须等到前面的指令完成。
指令冲突(instruction hazard):可执行指令的延迟使得流水线停止
结构性冲突(struct hazard):两个正在执行的指令同时使用一个硬件资源的情况
数据依赖性(data dependency)(注-大题)
三种方法:停顿与气泡,转发,软件
对应上述的数据冲突,例如Add R2,R3,#100
Subtract R9,R2,#30
解决此问题需要使用B1中存储的Subtract指令的源寄存器标识符和B2中的Add指令的目标寄存器标识符
具体时钟如下:
由于数据依赖,subtract必须停顿(stall),Add指令向前移动,在B2中为Subtract留下一个空操作(NOP),空指令完成计算,访存,写回三步后,就产生了上图所示的D段,即气泡(bubble),此外,D中还需要一个周期来获取刚写入的数据,下一条指令只能停留在F阶段。
操作数转发(operand forwanding)(注)
c的结束到c的开始,m的结束到c的开始
我们使用操作数转发技术来缓解上述延迟。
我们仔细分析下气泡带来的延迟:Subtract指令暂停3个周期后继续执行,但实际上Subtract的源寄存器需要的最新信息在第三个周期就被Add计算出来放入了B3中。
因此,Subtract可以不被延迟,如下图: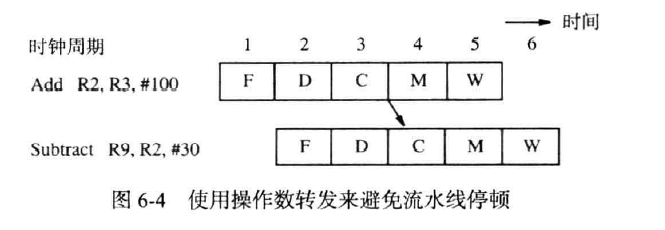
对此,我们更新图8: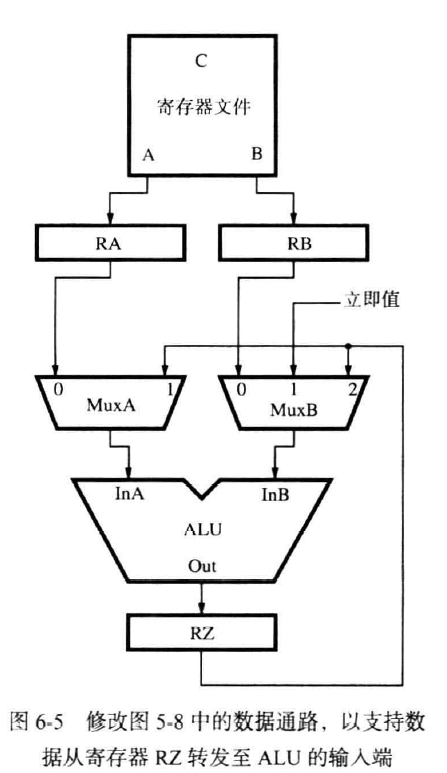
添加了MuxA,选择使用读取到的值或是从RZ中得到的计算后的值,MuxB同理,为了对三指令同样适配,如Add R2,R3,#100
Or R4,R5,R6
Subtract R9,R2,#30
中间隔了一个指令,此时,RZ的内容移动到RY,且RZ也被更新,所以在MuxA和MuxB上再加一个选择:选择RY的值
时钟如下图: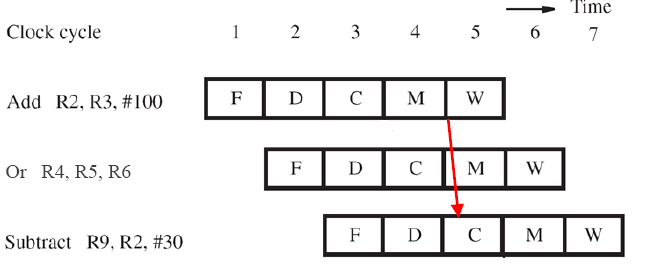
用软件处理数据依赖性
编译器检测指令间的关联性,在第一个指令后插入多个流水的空指令,时间延迟与气泡一致。但这些空指令可以被之后的更优先度指令替代,这需要编译器的考量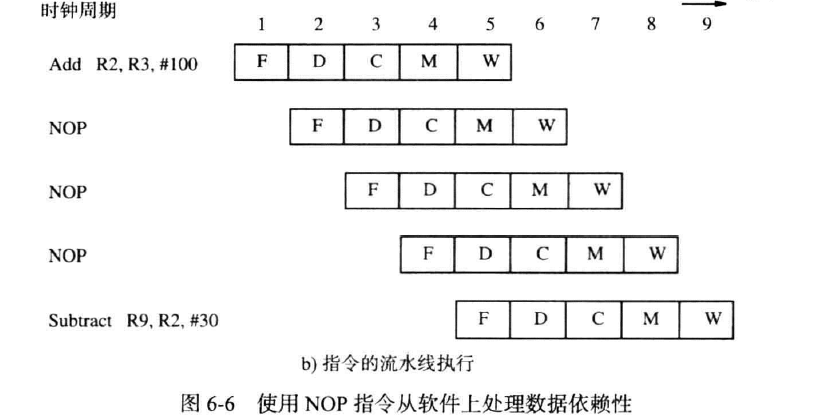
存储器延迟(注-)
存储器延迟(如Miss)时也会引起流水线停顿,一次存储器延迟可能长达十多个周期,后续的指令也需要等待此延迟,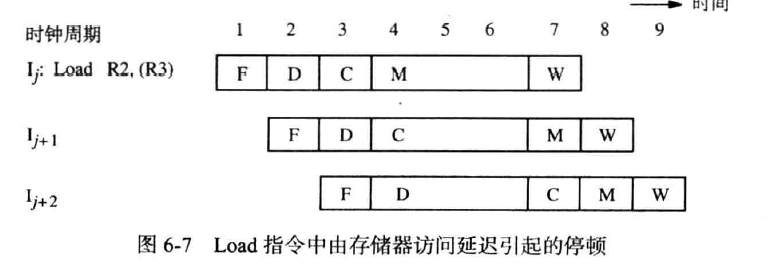
但不能使用数据依赖性中显示的那样,因为从存储器中读取的在第五个周期装入RY(B4)中才可用,为此,后面的指令必须延迟一个周期,如下图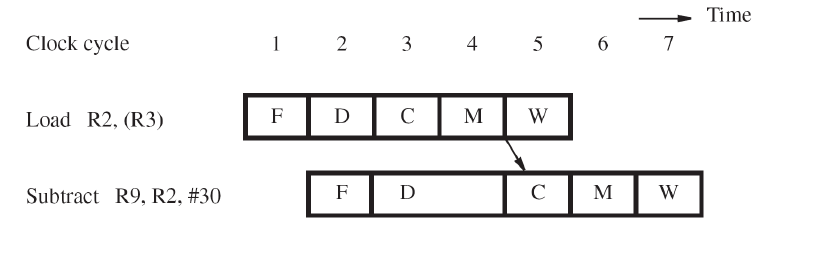
延迟译码阶段使得上一条指令的访存紧邻下一条指令的计算阶段
软件处理
编译器可以在这两条指令间插入一条有用的指令,若找不到这样一条可用的指令,则引入一个周期的停顿,再否则,引入NOP
结构性冲突(资源冲突)
当取址和访存对同一个缓存操作时,需要为取指令和访问内存两步分别设置单独的缓存(separate caches),以便两步能够同时进行
转移延迟
在循环中,转移指令正在执行时,物理结构上的下一条指令执行,但逻辑上应该执行的指令没有执行
无条件延迟
转移指令在提取,译码,计算偏移量后得到转移地址,即在第四步开始时逻辑上的下一条指令开始执行,而这其中执行的两条物理指令分别执行了提取,译码和提取,这两个周期的延迟称为转移代价(branch penalty),如图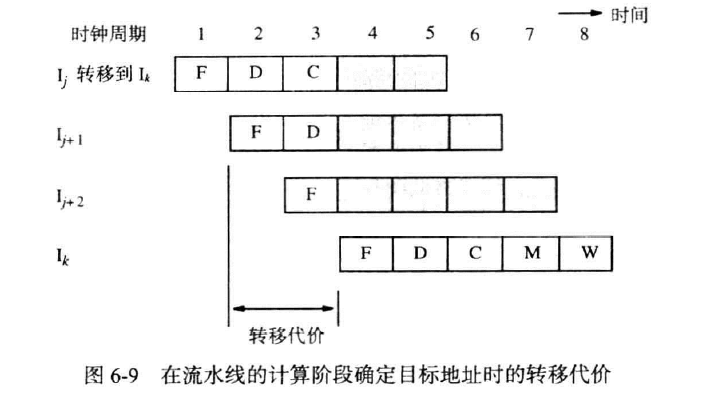
我们设法在译码阶段结束就输出转移目标地址,为此在译码阶段增加一个额外的加法器。图10中的加法器必须计算PC自增后的值,译码阶段的加法器直接提取指令某个字段计算转移地址,若译码阶段结束,证实指令是转移指令,则立即输出译码计算器的结果写入到PC中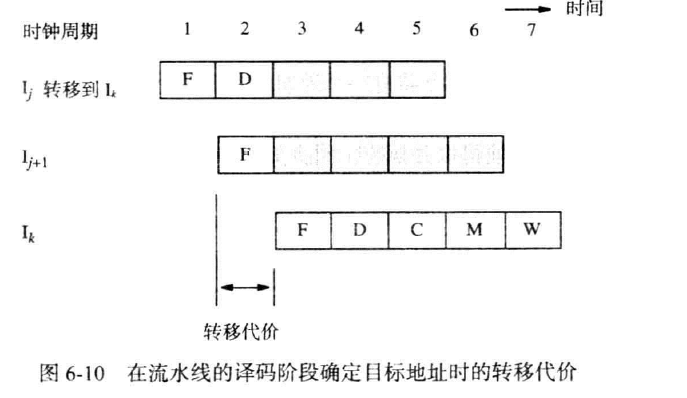
有如上结果,转移代价减少到一个周期
条件转移
对Branch_if_[R5]=[R6] LOOP必须尽快判断出条件成立与否
在译码阶段引入一个比较器,同样不加思考的比较与计算,若确实是转移指令,则立刻转移
转移延迟槽(branch delay slot)
在转移的基础上再尝试优化,我们将转移指令后面的指令称为转移槽,在转移槽中填充无关联性的指令或空指令,这是编译器的工作
抛弃原有转移延迟槽的内容是必须的,编译器要么装入允许的指令,要么填入空分支。
因为对后续指令的选择是对其的重排,把这种转移也称为延迟转移(delayed brancing)
习题
1 . A(n) is a situation in which the pipeline is stalled because the data to be operated on are delayed for some reason
数据冲突
2 . —- is any condition in which either the source or the destination operands of an instruction are not available at the time expected in the pipeline.
A. control hazard B. data hazard C. structural hazard D. instruction hazard
B
3 . About the data dependency in a pipeline, which is not true in the following? A. Operand forwarding can handle all data dependencies without the penalty of stalling the pipeline.
B. Compiler can detect data dependencies and deal with them by analyzing instructions.
C. Compiler puts explicit NOP instructions between instructions having a dependency.
D. Even with a cache hit and operand forwarding, the data dependency between “Load R2, (R3)” and “Subtract R9, R2, #30” will also cause onecycle stall.
A
4.如下
Load R1, 4(R2) |
1)Identify all the data dependencies in the above instruction sequence. For
each dependency, indicate the two instructions and the register that causes
the dependency.
There are three data dependencies in this instruction sequence:
•
Sub instruction depends on Load instruction for register R1
•
And instruction depends on Load instruction for register R1
•
Or instruction depends on Sub instruction for register R4
注意的点:
部分指令的源寄存器和目的寄存器顺序颠倒,如Store,请注意
2)Assume that the pipeline does not use operand forwarding. Also assume that the only sources of pipeline stalls are the data hazards. Draw a diagram thatrepresents instruction flow through the pipeline during each clock cycle.
遇到的问题可能有:
- 题意要求不使用转发,也只有数据延迟
- 数据放入寄存器文件中后需要一个周期才能读取
- 前一个阶段完成后下一个指令才能继续此阶段
3)Assume that the pipeline uses operand forwarding. The pipeline hardware is
similar to figure 2 above, but add separate forwarding paths from the outputs
of stage 3 and stage 4 to the input of stage 3. Draw a diagram that represents
the flow of instructions through the pipeline during each clock cycle. Indicate
operand forwarding by arrows.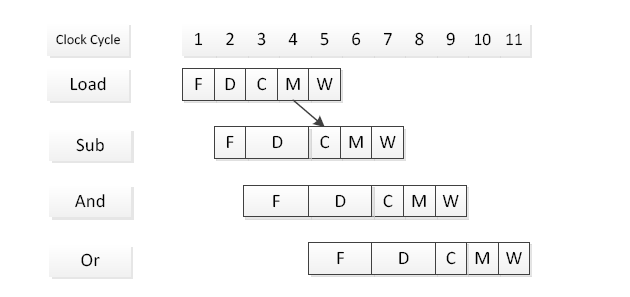
遇到的问题可能有: - 题意要求使用转发
- Load指令中R1的值最早四阶段才可以使用
- 一指令五阶段无转发通路,故And指令需要延后一个周期
- 二指令三阶段不能转发,够不到第四指令的三阶段
注:此章剩余内容不考
基本输入输出(Basic input/output)
访问(access)IO设备
存储器(memory)映射I/O
我们将IO设备视为主存的延伸,因此,IO与主存共享同一片寻址空间,IO也必须存在可以直接寻址的单元,我们把这些单元称为I/O寄存器,这种方法称为存储器映射I/O。
就像处理器不知道缓存的存在一样,可以把存储器映射视为处理器不知道I/O的存在,所有的代码也不区分I/O与否
不同于虚拟内存,存储器映射把IO视为主存的一部分,扩大了主存的内容;而虚拟内存则是一种分配主存资源的手段。即:讲究效率使用虚拟内存,讲究空间使用存储器映射
评价
优点
任何可以访问内存的机器指令都可以用来将数据传输至 I/O 设备或从 I/O 设备传输数据。
缺点
宝贵的内存地址空间被用完
分离式I/O(separated IO)
与主存的寻址空间分离,使用特殊的机器指令,逻辑上有区别于总线的数据线,但不意味着物理上的数据线也是分离的
优点:I/O 设备连接与处理很少的地址线
I/O设备接口(IO device interface)
一个I/O设备通过I/O设备接口的电路连接到互联网络中,这个电路包含了数据(data)寄存器,状态(state)寄存器,控制(control)寄存器三种寄存器,可以被CPU直接访问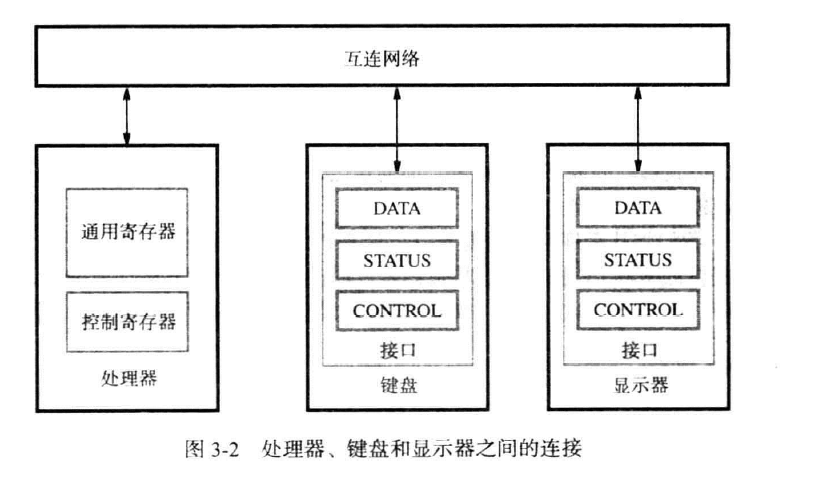
习题
1 . About memory-mapped I/O, which of the following is not true?
A. The I/O devices and the memory share the same address space.
B. Any machine instruction that can access memory can be used to transfer
data to or from an I/O device.
C. Valuable memory address space is used up.
D. I/O devices deal with few address lines.
D
2 . What is the difference between memory-mapped I/O and isolated I/O?
Memory-mapped I/O:
• The I/O devices and the memory share the same address space.
• No special commands for I/O. Any machine instruction that can access memory
can be used to transfer data to or from an I/O device.
• Valuable memory address space is used up.
Isolated I/O:
• Separate address spaces
• Special I/O instructions to perform I/O transfers.
• I/O devices deal with few address lines.
程序控制I/O(program-controlled IO)
我们通过软件实现自动读取键盘的数据,存储到主存后显示在屏幕上等一系列行为,这种方法称为程序控制I/O
以键盘输入到显示在屏幕的过程为例,读取键盘并将数据传输到主存对速度的要求远远低于计算机将数据传送到屏幕时对速度的要求。这种速度上高度的差异就催生了同步机制(synchronization mechanism)
一种同步机制是信号协议,每次显示或读取信息,都要等到信号传来才可以进行。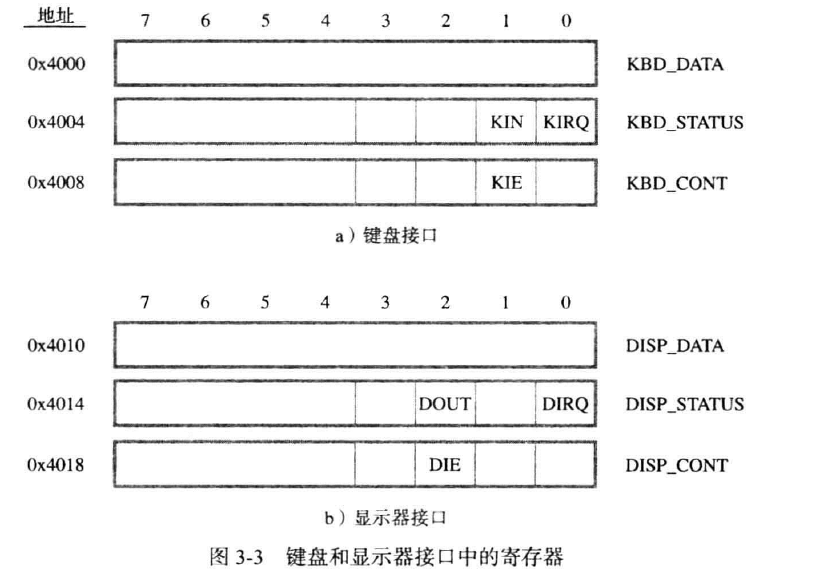
对键盘:KBD_DATA作为8位寄存器,存储按下的对应的字符的ASCII码,KBD_STATUS是状态寄存器,其中的KIN表示是否有按键被按下,若有,则置为1.
处理器轮询(poll) KIN位,若是1,则读取KBD_DATA的内容。
对显示屏同理,DOUT位表示显示器准备好接收下一个数据。
一个RISC的示例
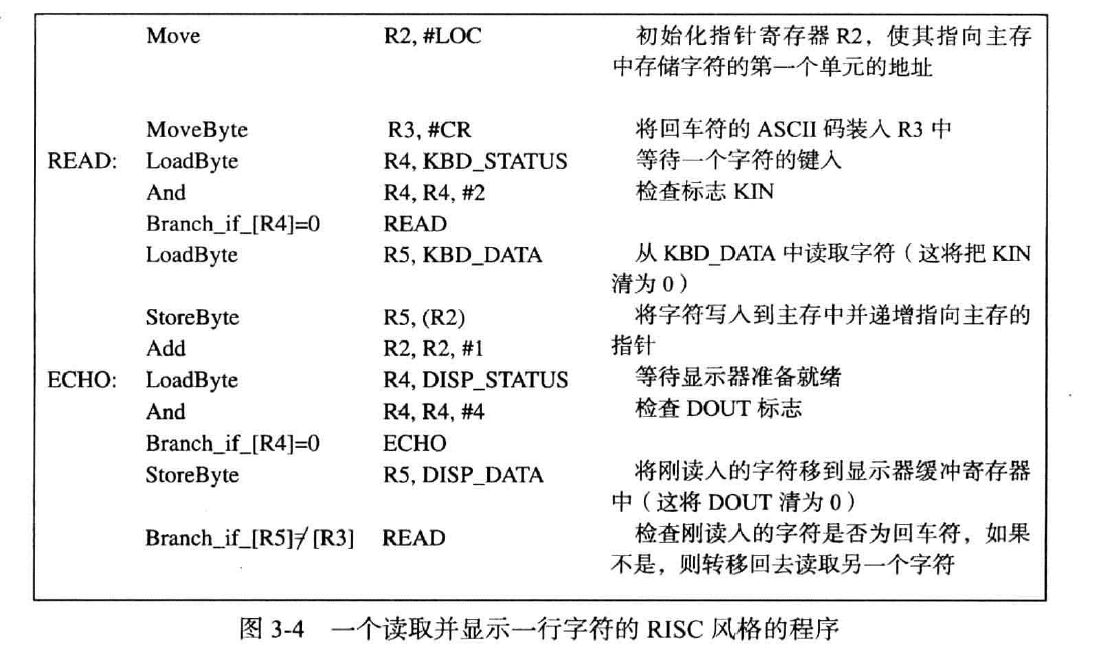
其中:
对键盘的输入
- R2存储了指向主存中存储I/O设备数据的第一个存储单元的地址,每次累加以指向下一个节点
- R3存储了指示存储结束的尾字符
- R4存储了键盘的状态位,在此后的And指令中,与2以表示对KIN位状态的考察
- R5存储了当前读取的字符,之后要存储到主存中去
对显示的输出
- R4存储了显示的状态位,与4表示对第三位的值是否为1的考察
- R5将刚刚存储的数据再次传入到输出的数据寄存器中
- 考察是否倒了结尾,否则继续读取
一个CISC的示例
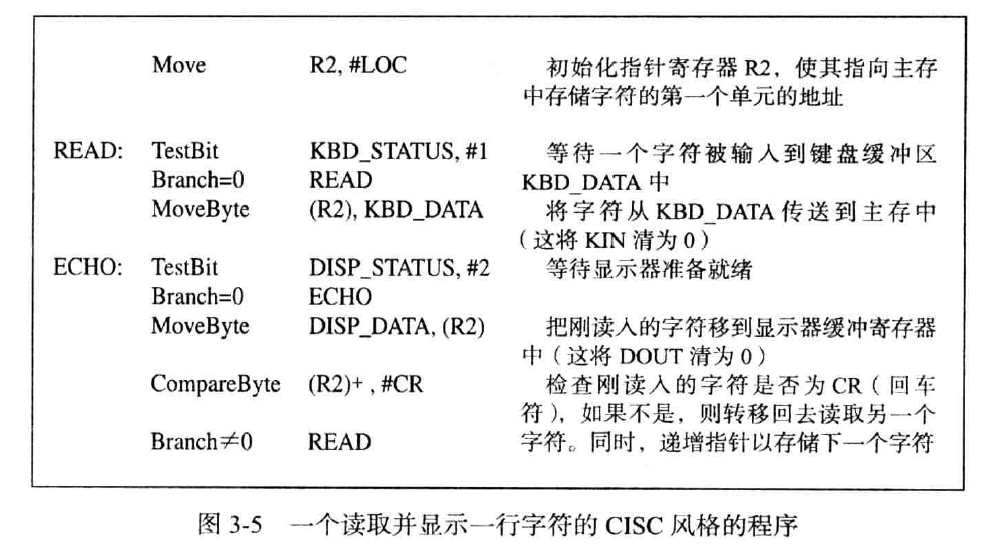
同上,不同点为CISC可以直接访问主存中的寄存器,包括其单个位数,以及其可以自增
中断(interrupt)(硬件控制的I/O或中断控制的IO)
我们使用中断来避免程序控制的I/O陷入不断的循环中。
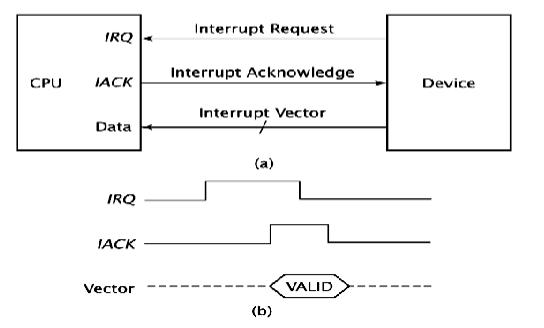
IO设备可以发送一个中断请求(interrupt request) 的信号给处理器,处理器中断当前指令的执行,转而响应中断要求执行中断服务程序(interrupt service routine),这就是中断。
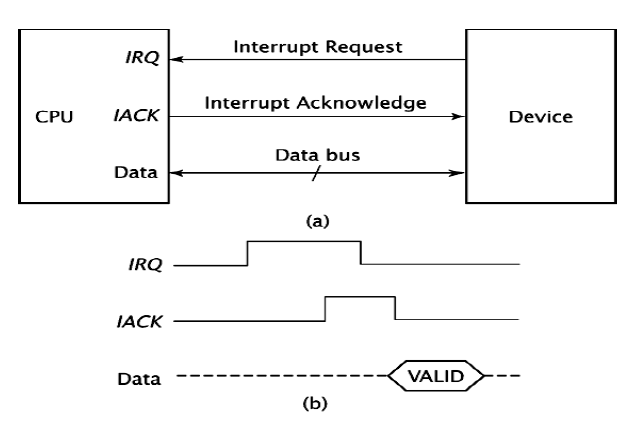
处理器接收到中断请求时,必须发送信号表示此请求被执行,使得IO设备撤销中断请求的信号,这个信号称为中断确认信号(interrupt acknowledges),或是向对应的IO设备传输数据。
中断延迟(interrupt latency):从接收到中断请求信号到开始执行中断服务程序的延迟时间
中断和子程序调用
子程序是程序执行中常规的一部分,处理器预先知道子程序调用会涉及哪些寄存器的数据,比如家人让你去倒垃圾,你预先就知道了这个步骤会涉及哪个方面,从而可以不加保护的进行子程序调用,而只需要保存PC的内容
中断时突发的情况,为应对危险,处理器必须存储一些状态信息和PC(即返回地址,一般存储在指定的通用寄存器或处理器堆栈,即进程控制块(PCB))来应对突发的修改。
处理器一般自动保存维持程序执行的最小信息量,为PC和处理器状态寄存器的内容,若需要保存额外的信息,需要手动指令给出。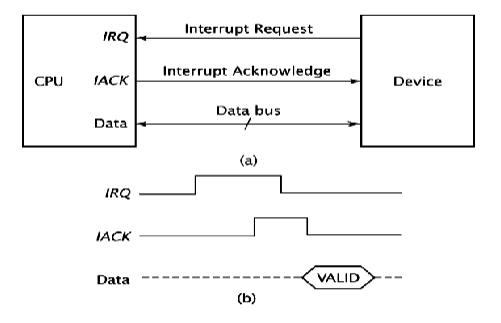
保存类型
- 保存所有寄存器的内容
- 保存维持程序执行的最小信息量,为PC和处理器状态寄存器的内容。
- 复制处理器的寄存器组,中断服务程序使用另一个不同的寄存器组,称为影子寄存器
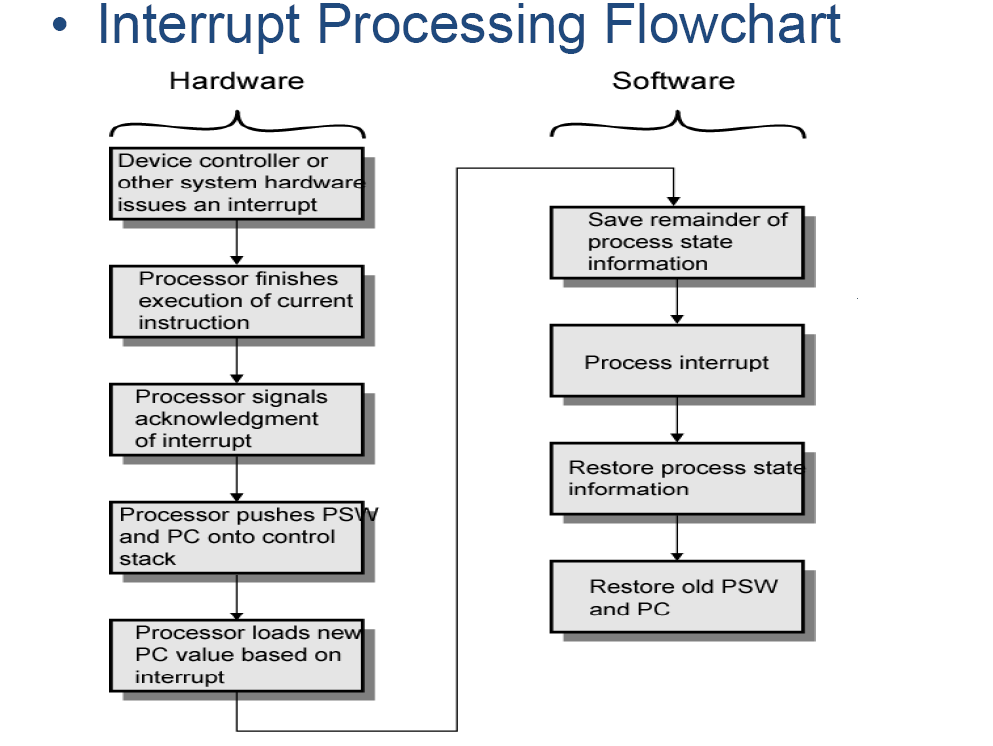
如图,硬件部分负责存储PC和PSW(程序状态字),软件部分负责存储其余的进程信息,处理中断,恢复自己存储的数据。
软件部分即程序部分,程序决定了要保留哪些信息,决定了中断服务程序的内容以及如何恢复其他数据,以及何时结束中断服务程序中断的允许与禁止(enable and disabling interrupts)
单设备
某些时候我们希望程序按设定好的顺序执行,所以必须设定在某些时候,处理器不接受中断请求。
处理器的状态寄存器(PS) 中存在当前操作状态的信息,其中一位IE被分配为允许/禁止中断,IE为1时接受中断,反之全部忽略。IE也叫中断允许位(interrupt-enable bit)。
IO设备的控制寄存器中也有一位表示能否发出中断,此位为1时才会发出中断请求,即KIE,DIE。
处理器在处理一个中断前会自动禁止中断,PS中的IE的值为1,且被保存。之后IE被更新为0,直到执行中断返回指令时,IE才会变为之前保存的数据1
有顺序:发出中断请求->中止指令,存储信息->IE置为0->通知设备中断请求被识别->中断结束后恢复原数据
习题
1 . In an interrupt process, the usage of saving PC is .
A. to make CPU find the entry address of the interrupt service routine
B. to continue from the program breakpoint when returning from interrupt
C. to make CPU and peripherals working in parallel
D. to enable interrupt nesting
B
2 . What is interrupt? What advantage does Interrupt-Driven I/O have over
Program-Controlled I/O?
Solution:
An interrupt is an event that causes the processor to stop its current program
execution and switch to performing an interrupt service routine.
Interrupt-Driven I/O allows the computer to process other tasks while waiting
for I/O.
多设备(multiple)
若多台设备刚好在同一时间发出中断请求,处理器必须确定哪个仪器发出了哪个中断请求,必须确定获取哪个中断服务程序的起始地址等。
多中断请求线(Multiple Interrupt-request Lines)
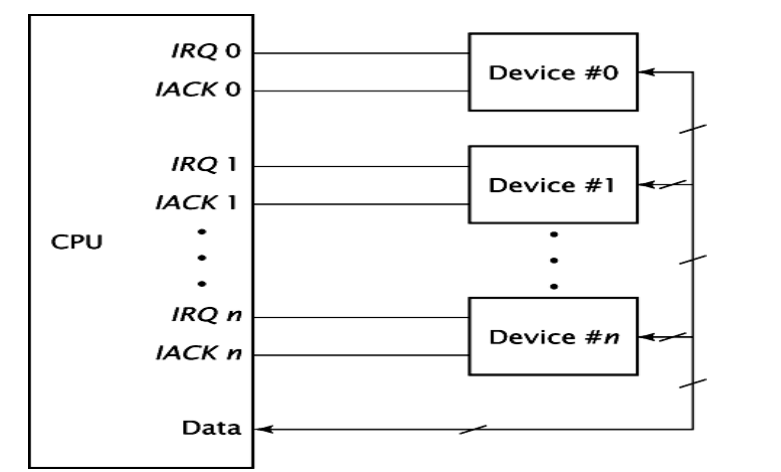
快捷的根据优先级查找中断,但每个中断线后可能有多个IO设备
轮询(polling)
为每个IO设备的状态寄存器添加一位IRQ,表示设备是否发出了中断请求。一旦一个中断请求被发出,我们就通过轮询此状态位来确定是哪个IO设备发出了中断请求
向量中断(vector interrupt)
为了减少轮询花费的时间,中断请求中会包含此设备的信息,或设备通过互联网络发送专门的代码标识自己。处理器的电路会从中得到设备提供的中断服务程序的地址。
多设备的中断服务程序的地址通常放置在主存的中断向量表(interrupt vector table) 中,表中每一项叫中断向量(interrupt vector),他是指向中断服务地址的指针。
中断嵌套(interrupt nesting)
处理器处理中断时会停止接受其他的中断请求,但有时某些请求不能被延迟执行太久,我们必须在中断服务程序中执行另一个中断服务请求,这就是中断嵌套。
这意味着IO设备必须存在一个优先级,在处理低优先级时必须立刻处理高优先级,且必须维护一个堆栈存放各级的中断信息,存放必须在IE位设置成1之前。
处理器处理中断请求时,会把自身的优先级提升到正在处理的中断的优先级,遇到中断时,比较优先级后再确定是否要处理。
同时中断(simultanenous interrupt)
当两个或多个中断同时到来时,需要选择其中一个中断执行。
处理器轮询IO设备的状态寄存器,轮询的顺序即是优先级的顺序
硬件轮询(Daisy chain菊花链/herdware poll)
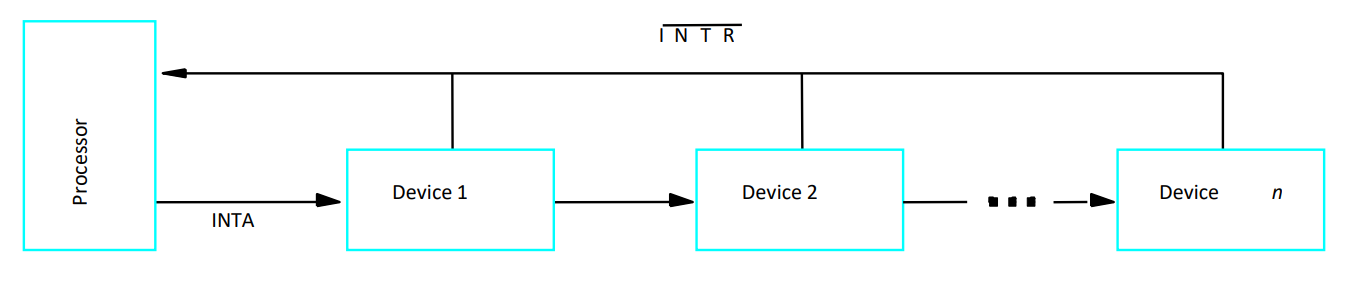
所有IO设备被菊花链以链表的形式连接,距离处理器最近的优先级最高
优先级组(priority group)

将共享中断请求线的多个设备分成不同的优先级组。在这种方式下,首先确定优先级组的优先级顺序,当有中断请求时,先确定是哪个优先级组发出的请求,然后在该优先级组内部再采用其他方式(如软件轮询或硬件轮询)来确定具体的设备
习题
1 . n the process of determining which device is requesting an interrupt, the device identifies itself directly by sending a signal or a binary code to the processor. This approach is called
A. polling B. non-vectored interrupt C. vectored interrupt D. interrupt vector
D
2 . The following figure shows the interface of a keyboard. Write functions of (1) KIN (2) KIRQ (3) KIE.
The KIN bit is the status flag for the processor to read to determine when a
character code has been placed in KBD_DATA. If KIN=1, then the character
has been in KBD_DATA, otherwise, KIN=0.
(2) The KIRQ bit is the status flag whether the keyboard is requesting an
interrupt. If KIRQ=1, it shows that the keyboard raises an interrupt,
otherwise, KIRQ=0.
(3) The KIE bit is the bit to control whether the keyboard can raise an interrupt.
If KIE=1, then the keyboard is placed into a mode in which it is allowed to
interrupt the processor whenever it is ready for an I/O transfer.
DMA
我们在第八章就已经简单提及过DMA了,我们现在仔细讨论这个设备
假设处理器要把磁盘内容传到主存,需要把磁盘内容写入缓存,再写入寄存器,最后写入主存,故使用DMA避免复杂的操作。
DMA接管了主存和IO设备之间的数据传输,当传输完毕后,DMA向处理器发送中断,通知其收回总线的授权
CPU将信息传输到DMA controller(DMAC) 中,信息包括:数据在设备上的地址,数据在主存中的地址,传输的块的大小,传输方向,传输模式
DMAC
DMAC会为传输提供内存地址,控制传输的信号,为连续的字递增内存地址,记录传输的次数
传输模式
- brust突发,也叫块传输,应用于一次性大片传输。但会占用总线,CPU此时无法使用总线
缺点:会使处理器在相对较长的时间内处于限制状态 - cycle steal周期窃取,每个周期占用一定的传输份额进行传输
DMA不断的获取总线的使用权限,但每次只传输一个字节的数据,直到所有数据被传输完毕 - Transparent Mode透明模式:只在处理器不执行有关总线的指令时才获取总线权限传输
优点:处理器永远不会停止执行其程序
缺点:电路可能会相当复杂
当DMA准备好要传输数据时,向处理器请求总线的使用权限,即发送BR(Bus Request) 信号,总线仲裁器(Bus arbiter) 处理申请总线使用的请求。一旦收到BG(Bus Grant) 的信号,DMA就可以开始工作了。
配置
单总线,分离式DMAC( Single-bus, Detached DMA Controlle)
传输方向:IO->DMA,DMA->主存
CPU被中断两次
单总线,集成式DMAC(Single-bus, Integrated DMA Controller)
能与多个IO设备同时交互且集成在一起,只使用一个总线
传输方向:DMA->主存
CPU被中断一次
独立IO总线(Separate I/O bus)
使用独立的总线,只要接口合适,可以支持所有的IO
传输方向:DMA->主存
CPU被中断一次
习题
1 . Which method bypasses the CPU for certain types of data transfer?
A. Software interrupts
B. Polled I/O
C. Interrupted-driven I/O
D. Direct Memory Access (DMA)
D
2 . —- is used for high-speed block transfers directly between an external device and the main memory.
A. Program-controlled I/O
B. Interrupt-driven I/O
C. DMA approach
D. Event-driven
C
3 . Once the DMA controller obtains access to the system bus, it transfers one byte of data and then returns the control of system bus to the processor. This is
A. burst mode B. block mode C. cycle stealing mode D. transparent mode
C

